



Badge source
Key findings: People with the highest credit score, and have a co-applicant, are more likely to receive a large loan amount.
- Business problem
- Data source
- Methods
- Tech Stack
- Quick glance at the results
- Lessons learned and recommendation
- Limitation and what can be improved
- Run Locally
- Explore the notebook
- Deployment on streamlit
- App deployed on Streamlit
- Repository structure
- Contribution
- License
This app predicts how much of a loan will be granted to an applicant. The app uses different information about the applicant profile and predict how much will be approved. Usually the applicant with a higher credit score, a co-applicant will be granted a larger loan amount. It depends also on how much the applicant has requested.
- Exploratory data analysis
- Bivariate analysis
- Multivariate correlation
- S3 bucket model hosting
- Model deployment
- Python (refer to requirement.txt and yml file in the assets folder for the packages used in this project)
- Streamlit (interface for the model)
- AWS S3 (model storage)
Correlation between the features.

RMSE of random forest with the best hyperparameters.

We have an RMSE on a range between 0 and 400000
Top features of random forest with the best hyperparameters.

Least useful features of random forest with the best hyperparameters.

Top 3 models (with default parameters)
| Model with the best hyperparameter | RMSE (range between 0 and 400000) |
|---|---|
| Random Forest | 20791.86 |
| Bagging | 20780.02 |
| Gradient Boosting | 26974.42 |
-
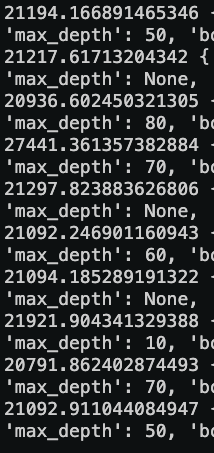
The final model used is: Random Forest
-
Metrics used: RMSE
-
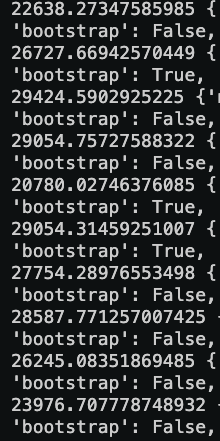
Why choose random forest while bagging yield the best results?: Comparing the RMSE while tuning the parameters, random forest produced the lowest RMSE constitenly.
RMSE random forest
RMSE bagging


- Based on the analysis on this project, we found out that the loan amount that will be granted is determined mainly by the loan amount requested, credit score and a co-applicant. The least important features are expenses types and gender.
- Recommendation would be to focus more on the most predictive feature when looking at the applicant profile, and pay less attention on the least predictive features.
- The dataset lack a metadata about the features. (What expenses types mean? What does property type 1, 2, 3, 4 mean?)
- Retrain the model without the least predictive features
- Hyperparameter tuning: I used RandomSearchCV to save time but could be improved by couple of % with GridSearchCV.
Initialize git
git initClone the project
git clone https://github.com/semasuka/Loan-amount-prediction-regression.gitenter the project directory
cd Loan-amount-prediction-regressionCreate a conda virtual environment and install all the packages from the environment.yml (recommended)
conda env create --prefix <env_name> --file assets/environment.ymlActivate the conda environment
conda activate <env_name>List all the packages installed
conda listStart the streamlit server locally
streamlit run loan_amount_app.pyIf you are having issue with streamlit, please follow this tutorial on how to set up streamlit
To explore the notebook file here
To deploy this project on streamlit share, follow these steps:
- first, make sure you upload your files on Github, including a requirements.txt file
- go to streamlit share
- login with Github, Google, etc.
- click on new app button
- select the Github repo name, branch, python file with the streamlit codes
- click advanced settings, select python version 3.9 and add the secret keys if your model is stored on AWS or GCP bucket
- then save and deploy!

Video to gif tool
├── assets
│ ├── bottom10.png <- A picture of the bottom 10 features
│ ├── environment.yml <- list of all the dependencies with their versions(for conda environment)
│ ├── gif_streamlit.gif <- gif file used in the README
│ ├── heatmap.png <- heatmap image used in the README
│ ├── loan_amount_banner.png <- banner image used in the README
│ ├── rmse.png <- Image of the best RMSE from the random forest used in the README
│ ├── rmse_bagging.png <- Image of the bagging RMSE used in the README
│ ├── rmse_rand_forest.png <- Image of the random forest RMSE used in the README
│ ├── top10.png <- A picture of the top 10 features
│
├── datasets
│ ├── test.csv <- the test data
│ ├── train.csv <- the train data
│
│
├── .gitignore <- used to ignore certain folder and files that won't be commit to git.
│
│
├── LICENSE <- license file.
│
│
├── Loan_amount_prediction.ipynb <- main python notebook where all the analysis and modeling are done.
│
│
├── README.md <- this readme file.
│
│
├── loan_amount_app.py <- file with the model and streamlit component for rendering the interface.
│
│
├── requirements.txt <- list of all the dependencies with their versions(used for Streamlit).
Pull requests are welcome! For major changes, please open an issue first to discuss what you would like to change or contribute.
MIT License
Copyright (c) 2022 Stern Semasuka
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Learn more about MIT license