
Package repository for Voltron: Language-Driven Representation Learning for Robotics. Provides code for loading pretrained Voltron, R3M, and MVP representations for adaptation to downstream tasks, as well as code for pretraining such representations on arbitrary datasets.
This repository is built with PyTorch; while specified as a dependency for the package, we highly recommend that
you install the desired version (e.g., with accelerator support) for your given hardware and environment
manager (e.g., conda).
PyTorch installation instructions can be found here. This repository should work with PyTorch >= 1.12. Releases before 1.1.0 have been thoroughly tested with PyTorch 1.12.0, Torchvision 0.13.0, and Torchaudio 0.12.0. Note: Releases 1.1.0 and after assume PyTorch 2.0!
Once PyTorch has been properly installed, you can install this package via PyPI, and you're off!
pip install voltron-roboticsYou can also install this package locally via an editable installation in case you want to run examples/extend the current functionality:
git clone https://github.com/siddk/voltron-robotics
cd voltron-robotics
pip install -e .Voltron Robotics (package: voltron) is structured to provide easy access to pretrained Voltron models (and
reproductions), to facilitate use for various downstream tasks. Using a pretrained Voltron model is easy:
from torchvision.io import read_image
from voltron import instantiate_extractor, load
# Load a frozen Voltron (V-Cond) model & configure a vector extractor
vcond, preprocess = load("v-cond", device="cuda", freeze=True)
vector_extractor = instantiate_extractor(vcond)()
# Obtain & Preprocess an image =>> can be from a dataset, or camera on a robot, etc.
# => Feel free to add any language if you have it (Voltron models work either way!)
img = preprocess(read_image("examples/img/peel-carrot-initial.png"))[None, ...].to("cuda")
lang = ["peeling a carrot"]
# Extract both multimodal AND vision-only embeddings!
multimodal_embeddings = vcond(img, lang, mode="multimodal")
visual_embeddings = vcond(img, mode="visual")
# Use the `vector_extractor` to output dense vector representations for downstream applications!
# => Pass this representation to model of your choice (object detector, control policy, etc.)
representation = vector_extractor(multimodal_embeddings)Voltron representations can be used for a variety of different applications; in the
voltron-evaluation repository, you can find code for adapting Voltron
representations to various downstream tasks (segmentation, object detection, control, etc.); all the applications from
our paper.
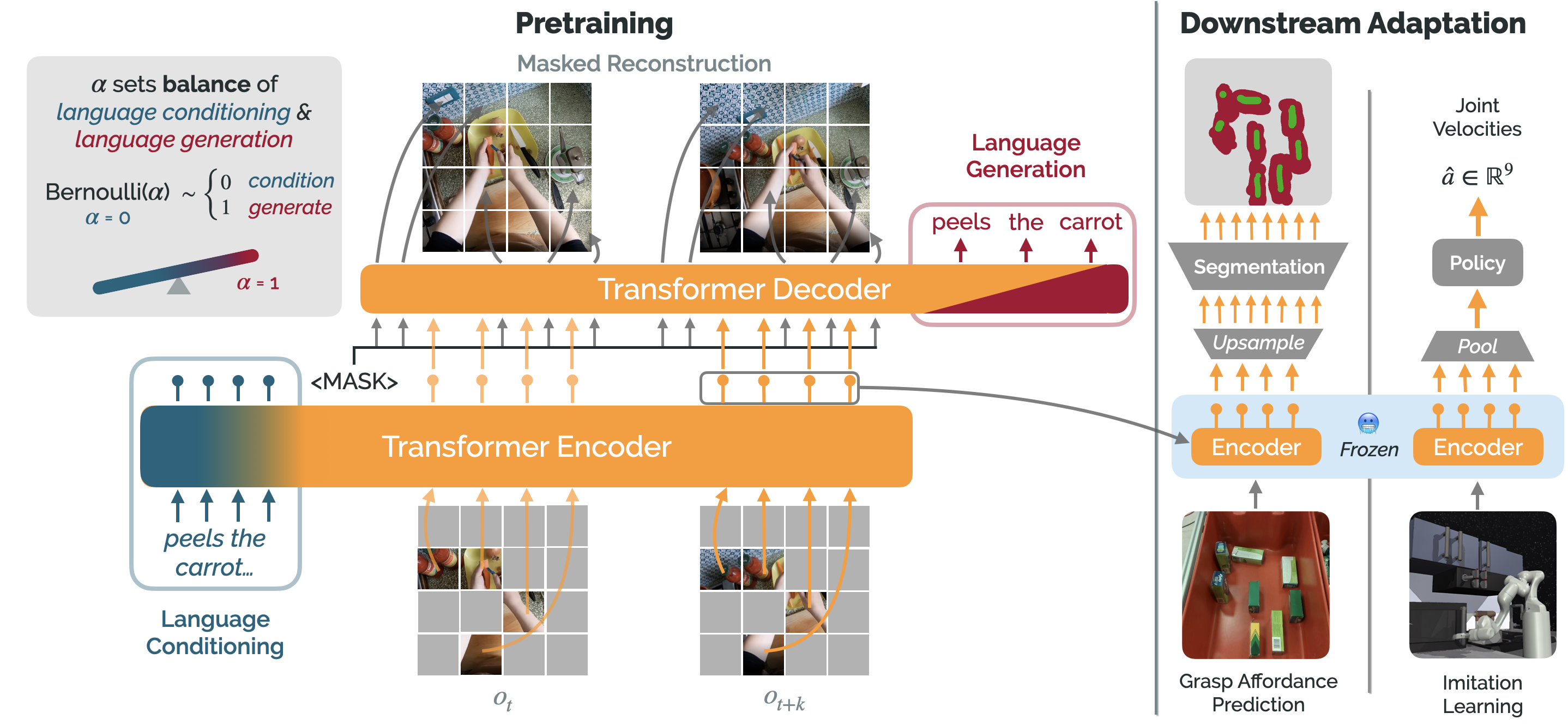
The package voltron provides the following functionality for using and adapting existing representations:
Returns the name of available Voltron models; right now, the following models (all models trained in the paper) are available:
v-cond– V-Cond (ViT-Small) trained on Sth-Sth; single-frame w/ language-conditioning.v-dual– V-Dual (ViT-Small) trained on Sth-Sth; dual-frame w/ language-conditioning.v-gen– V-Gen (ViT-Small) trained on Sth-Sth; dual-frame w/ language conditioning AND generation.r-mvp– R-MVP (ViT-Small); reproduction of MVP trained on Sth-Sth.r-r3m-vit– R-R3M (ViT-Small); reproduction of R3M trained on Sth-Sth.r-r3m-rn50– R-R3M (ResNet-50); reproduction of R3M trained on Sth-Sth.v-cond-base– V-Cond (ViT-Base) trained on Sth-Sth; larger (86M parameter) variant of V-Cond.
Returns the model and the Torchvision Transform needed by the model, where name is one of the strings returned
by voltron.available_models(); this in general follows the same API as
OpenAI's CLIP.
Voltron models (v-{cond, dual, gen, ...}) returned by voltron.load() support the following:
Returns a sequence of embeddings corresponding to the output of the multimodal encoder; note that lang can be None,
which is totally fine for Voltron models! However, if you have any language (even a coarse task description), it'll
probably be helpful!
The parameter mode in ["multimodal", "visual"] controls whether the output will contain the fused image patch and
language embeddings, or only the image patch embeddings.
Note: For the API for the non-Voltron models (e.g., R-MVP, R-R3M), take a look at
examples/verify.py; this file shows how representations from every model can be extracted.
See examples/usage.py and the voltron-evaluation
repository for more examples on the various ways to adapt/use Voltron representations.
Before committing to the repository, make sure to set up your dev environment! Here are the basic development environment setup guidelines:
-
Fork/clone the repository, performing an editable installation. Make sure to install with the development dependencies (e.g.,
pip install -e ".[dev]"); this will installblack,ruff, andpre-commit. -
Install
pre-commithooks (pre-commit install). -
Branch for the specific feature/issue, issuing PR against the upstream repository for review.
Additional Contribution Notes:
-
This project has migrated to the recommended
pyproject.tomlbased configuration for setuptools. However, as some tools haven't yet adopted PEP 660, we provide asetup.pyfile. -
This package follows the
flat-layoutstructure described insetuptools. -
Make sure to add any new dependencies to the
project.tomlfile!
High-level overview of repository/project file-tree:
docs/- Package documentation & assets - including project roadmap.voltron- Package source code; has all core utilities for model specification, loading, feature extraction, preprocessing, etc.examples/- Standalone examples scripts for demonstrating various functionality (e.g., extracting different types of representations, adapting representations in various contexts, pretraining, amongst others)..pre-commit-config.yaml- Pre-commit configuration file (sane defaults +black+ruff).LICENSE- Code is made available under the MIT License.Makefile- Top-level Makefile (by default, supports linting - checking & auto-fix); extend as needed.pyproject.toml- Following PEP 621, this file has all project configuration details (including dependencies), as well as tool configurations (forblackandruff).README.md- You are here!
Please cite our paper if using any of the Voltron models, evaluation suite, or other parts of our framework in your work.
@inproceedings{karamcheti2023voltron,
title={Language-Driven Representation Learning for Robotics},
author={Siddharth Karamcheti and Suraj Nair and Annie S. Chen and Thomas Kollar and Chelsea Finn and Dorsa Sadigh and Percy Liang},
booktitle={Robotics: Science and Systems (RSS)},
year={2023}
}