
Autonomous agents are designed to achieve specific objectives through self-guided instructions. With the emergence and growth of large language models (LLMs), there is a growing trend in utilizing LLMs as fundamental controllers for these autonomous agents. While previous studies in this field have achieved remarkable successes, they remain independent proposals with little effort devoted to a systematic analysis. To bridge this gap, we conduct a comprehensive survey study, focusing on the construction, application, and evaluation of LLM-based autonomous agents. In particular, we first explore the essential components of an AI agent, including a profile module, a memory module, a planning module, and an action module. We further investigate the application of LLM-based autonomous agents in the domains of natural sciences, social sciences, and engineering. Subsequently, we delve into a discussion of the evaluation strategies employed in this field, encompassing both subjective and objective methods. Our survey aims to serve as a resource for researchers and practitioners, providing insights, related references, and continuous updates on this exciting and rapidly evolving field.
To our knowledge, this is the first systematic survey paper in the field of LLM-based autonomous agents.
Paper link: A Survey on Large Language Model based Autonomous Agents
-
🔥 [9/8/2023] The second version of our survey has been released on arXiv.
Updated contents
-
📚 Additional References
- We have added 31 new works until 9/1/2023 to make the survey more comprehensive and up-to-date.
-
📊 New Figures
- Figure 3: This is a new figure illustrating the differences and similarities between various planning approaches. This helps in gaining a clearer understanding of the comparisons between different planning methods.
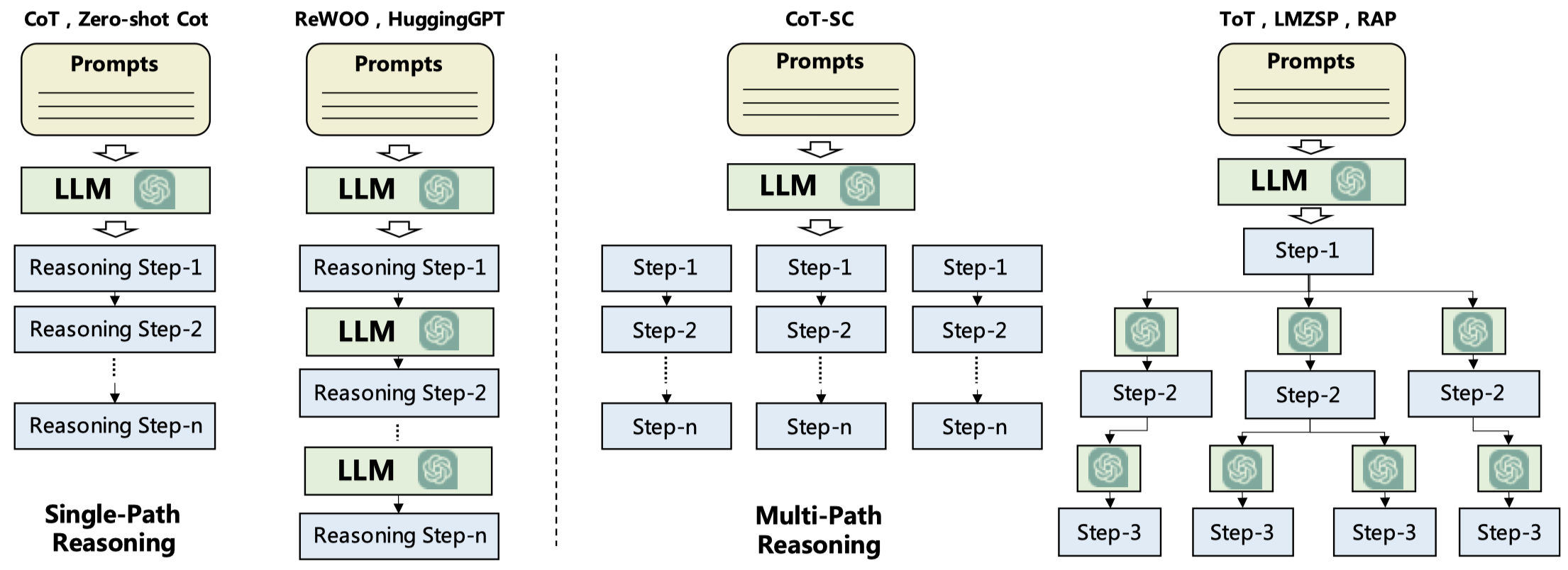
- Figure 4: This is a new figure that describes the evolutionary path of model capability acquisition from the "Machine Learning era" to the "Large Language Model era" and then to the "Agent era." Specifically, a new concept, "mechanism engineering," has been introduced, which, along with "parameter learning" and "prompt engineering," forms part of this evolutionary path.
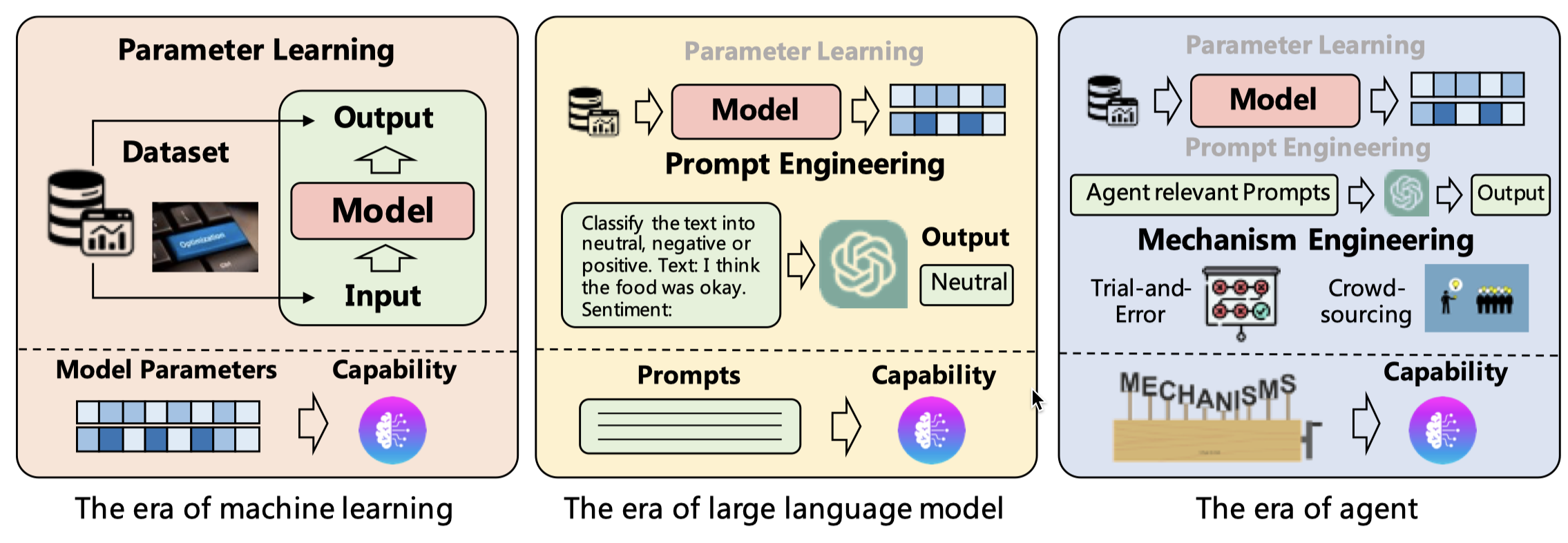
- Figure 3: This is a new figure illustrating the differences and similarities between various planning approaches. This helps in gaining a clearer understanding of the comparisons between different planning methods.
-
🔍 Optimized Classification System
- We have slightly modified the classification system in our survey to make it more logical and organized.
-
-
🔥 [8/23/2023] The first version of our survey has been released on arXiv.


- 🤖 Construction of LLM-based Autonomous Agent
- 📍 Applications of LLM-based Autonomous Agent
- 📊 Evaluation on LLM-based Autonomous Agent
- 🌐 More Comprehensive Summarization
- 👨👨👧👦 Maintainers
- 📚 Citation
- 💪 How to Contribute
- 🫡 Acknowledgement
- 📧 Contact Us

| Model | Profile | Memory | Planning | Action | CA | Paper | Code | |
| Operation | Structure | |||||||
| WebGPT | - | - | - | - | w/ tools | w/ fine-tuning | Paper | - |
| SayCan | - | - | - | w/o feedback | w/o tools | w/o fine-tuning | Paper | Code |
| MRKL | - | - | - | w/o feedback | w/ tools | - | Paper | - |
| Inner Monologue | - | - | - | w/ feedback | w/o tools | w/o fine-tuning | Paper | Code |
| Social Simulacra | GPT-Generated | - | - | - | w/o tools | - | Paper | - |
| ReAct | - | - | - | w/ feedback | w/ tools | w/ fine-tuning | Paper | Code |
| MALLM | - | Read/Write | Hybrid | - | w/o tools | - | Paper | - |
| DEPS | - | - | - | w/ feedback | w/o tools | w/o fine-tuning | Paper | Code |
| Toolformer | - | - | - | w/o feedback | w/ tools | w/ fine-tuning | Paper | Code |
| Reflexion | - | Read/Write/ Reflection |
Hybrid | w/ feedback | w/o tools | w/o fine-tuning | Paper | Code |
| CAMEL | Handcrafting & GPT-Generated | - | - | w/ feedback | w/o tools | - | Paper | Code |
| API-Bank | - | - | - | w/ feedback | w/ tools | w/o fine-tuning | Paper | Code |
| ViperGPT | - | - | - | - | w/ tools | - | Paper | Code |
| HuggingGPT | - | - | Unified | w/o feedback | w/ tools | - | Paper | Code |
| Generative Agents | Handcrafting | Read/Write/ Reflection |
Hybrid | w/ feedback | w/o tools | - | Paper | Code |
| LLM+P | - | - | - | w/o feedback | w/o tools | - | Paper | - |
| ChemCrow | - | - | - | w/ feedback | w/ tools | - | Paper | Code |
| OpenAGI | - | - | - | w/ feedback | w/ tools | w/ fine-tuning | Paper | Code |
| AutoGPT | - | Read/Write | Hybrid | w/ feedback | w/ tools | w/o fine-tuning | - | Code |
| SCM | - | Read/Write | Hybrid | - | w/o tools | - | Paper | Code |
| Socially Alignment | - | Read/Write | Hybrid | - | w/o tools | Example | Paper | Code |
| GITM | - | Read/Write/ Reflection |
Hybrid | w/ feedback | w/o tools | w/ fine-tuning | Paper | Code |
| Voyager | - | Read/Write/ Reflection |
Hybrid | w/ feedback | w/o tools | w/o fine-tuning | Paper | Code |
| Introspective Tips | - | - | - | w/ feedback | w/o tools | w/o fine-tuning | Paper | - |
| RET-LLM | - | Read/Write | Hybrid | - | w/o tools | w/ fine-tuning | Paper | - |
| ChatDB | - | Read/Write | Hybrid | w/ feedback | w/ tools | - | Paper | - |
| S3 | Dataset alignment | Read/Write/ Reflection |
Hybrid | - | w/o tools | w/ fine-tuning | Paper | - |
| ChatDev | Handcrafting | Read/Write/ Reflection |
Hybrid | w/ feedback | w/o tools | w/o fine-tuning | Paper | Code |
| ToolLLM | - | - | - | w/ feedback | w/ tools | w/ fine-tuning | Paper | Code |
| MemoryBank | - | Read/Write/ Reflection |
Hybrid | - | w/o tools | - | Paper | Code |
| MetaGPT | Handcrafting | Read/Write/ Reflection |
Hybrid | w/ feedback | w/ tools | - | Paper | Code |
- More papers can be found at More comprehensive Summarization.
- CA means the strategy of model capability acquisition.
| Title | Social Science | Natural Science | Engineering | Paper | Code |
| Drori et al. | - | Science Education | - | Paper | - |
| SayCan | - | - | Robotics & Embodied AI | Paper | Code |
| Inner monologue | - | - | Robotics & Embodied AI | Paper | Code |
| Language-Planners | - | - | Robotics & Embodied AI | Paper | Code |
| Social Simulacra | Social Simulation | - | - | Paper | - |
| TE | Psychology | - | - | Paper | Code |
| Out of One | Political Science and Economy | - | - | Paper | - |
| LIBRO | CS&SE | - | - | Paper | - |
| Blind Judgement | Jurisprudence | - | - | Paper | - |
| Horton | Political Science and Economy | - | - | Paper | - |
| DECKARD | - | - | Robotics & Embodied AI | Paper | Code |
| Planner-Actor-Reporter | - | - | Robotics & Embodied AI | Paper | - |
| DEPS | - | - | Robotics & Embodied AI | Paper | - |
| RCI | - | - | CS&SE | Paper | Code |
| Generative Agents | Social Simulation | - | - | Paper | Code |
| SCG | - | - | CS&SE | Paper | - |
| IGLU | - | - | Civil Engineering | Paper | - |
| IELLM | - | - | Industrial Automation | Paper | - |
| ChemCrow | - | Document and Data Management; Documentation, Data Managent; Science Education |
- | Paper | - |
| Boiko et al. | - | Document and Data Management; Documentation, Data Managent; Science Education |
- | Paper | - |
| GPT4IA | - | - | Industrial Automation | Paper | Code |
| Self-collaboration | - | - | CS&SE | Paper | - |
| E2WM | - | - | Robotics & Embodied AI | Paper | Code |
| Akata et al. | Psychology | - | - | Paper | - |
| Ziems et al. | Psychology; Political Science and Economy; Research Assistant |
- | - | Paper | - |
| AgentVerse | Social Simulation | - | - | Paper | Code |
| SmolModels | - | - | CS&SE | - | Code |
| TidyBot | - | - | Robotics & Embodied AI | Paper | Code |
| PET | - | - | Robotics & Embodied AI | Paper | - |
| Voyager | - | - | Robotics & Embodied AI | Paper | Code |
| GITM | - | - | Robotics & Embodied AI | Paper | Code |
| NLSOM | - | Science Education | - | Paper | - |
| LLM4RL | - | - | Robotics & Embodied AI | Paper | - |
| GPT Engineer | - | - | CS&SE | - | Code |
| Grossman et al. | - | Experiment Assistant; Science Education |
- | Paper | - |
| SQL-PALM | - | - | CS&SE | Paper | - |
| REMEMBER | - | - | Robotics & Embodied AI | Paper | - |
| DemoGPT | - | - | CS&SE | - | Code |
| Chatlaw | Jurisprudence | - | - | Paper | Code |
| RestGPT | - | - | CS&SE | Paper | Code |
| Dialogue shaping | - | - | Robotics & Embodied AI | Paper | - |
| TaPA | - | - | Robotics & Embodied AI | Paper | - |
| Ma et al. | Psychology | - | - | Paper | - |
| Math Agents | - | Science Education | - | Paper | - |
| SocialAI School | Social Simulation | - | - | Paper | - |
| Unified Agent | - | - | Robotics & Embodied AI | Paper | - |
| Wiliams et al. | Social Simulation | - | - | Paper | - |
| Li et al. | Social Simulation | - | - | Paper | - |
| S3 | Social Simulation | - | - | Paper | - |
| Dialogue Shaping | - | - | Robotics & Embodied AI | Paper | - |
| RoCo | - | - | Robotics & Embodied AI | Paper | Code |
| Sayplan | - | - | Robotics & Embodied AI | Paper | Code |
| ToolLLM | - | - | CS&SE | Paper | Code |
| ChatDEV | - | - | CS&SE | Paper | - |
| Chao et al. | Social Simulation | - | - | Paper | - |
| AgentSims | Social Simulation | - | - | Paper | Code |
| ChatMOF | - | Document and Data Management; Science Education |
- | Paper | - |
| MetaGPT | - | - | CS&SE | Paper | Code |
| Codehelp | - | Science Education | CS&SE | Paper | - |
| AutoGen | - | Science Education | - | Paper | - |
| RAH | - | - | CS&SE | Paper | - |
| DB-GPT | - | - | CS&SE | Paper | Code |
| RecMind | - | - | CS&SE | Paper | - |
| ChatEDA | - | - | CS&SE | Paper | - |
| InteRecAgent | - | - | CS&SE | Paper | - |
| PentestGPT | - | - | CS&SE | Paper | - |
| Codehelp | - | - | CS&SE | Paper | - |
| ProAgent | - | - | Robotics & Embodied AI | Paper | - |
- More papers can be found at More comprehensive Summarization.
| Model | Subjective | Objective | Benchmark | Paper | Code |
| WebShop | - | Environment Simulation; Multi-task Evaluation |
✓ | Paper | Code |
| Social Simulacra | Human Annotation | Social Evaluation | - | Paper | - |
| TE | - | Social Evaluation | - | Paper | Code |
| LIBRO | - | Software Testing | - | Paper | - |
| ReAct | - | Environment Simulation | ✓ | Paper | Code |
| Out of One, Many | Turing Test | Social Evaluation; Multi-task Evaluation |
- | Paper | - |
| DEPS | - | Environment Simulation | ✓ | Paper | - |
| Jalil et al. | - | Software Testing | - | Paper | Code |
| Reflexion | - | Environment Simulation; Multi-task Evaluation |
- | Paper | Code |
| IGLU | - | Environment Simulation | ✓ | Paper | - |
| Generative Agents | Human Annoation; Turing Test |
- | - | Paper | Code |
| ToolBench | Human Annoation | Multi-task Evalution | ✓ | Paper | Code |
| GITM | - | Environment Simulation | ✓ | Paper | Code |
| Two-Failures | - | Multi-task Evalution | - | Paper | - |
| Voyager | - | Environment Simulation | ✓ | Paper | Code |
| SocKET | - | Social Evaluation; Multi-task Evaluation |
✓ | Paper | - |
| Mobile-Env | - | Environment Simulation; Multi-task Evaluation |
✓ | Paper | Code |
| Clembench | - | Environment Simulation; Multi-task Evaluation |
✓ | Paper | Code |
| Dialop | - | Social Evaluation | ✓ | Paper | Code |
| Feldt et al. | - | Software Testing | - | Paper | - |
| CO-LLM | Human Annoation | Environment Simulation | - | Paper | Code |
| Tachikuma | Human Annoation | Environment Simulation | ✓ | Paper | - |
| WebArena | - | Environment Simulation | ✓ | Paper | Code |
| RocoBench | - | Environment Simulation; Social Evaluation; Multi-task Evaluation |
✓ | Paper | Code |
| AgentSims | - | Social Evaluation | - | Paper | Code |
| AgentBench | - | Multi-task Evaluation | ✓ | Paper | Code |
| BOLAA | - | Environment Simulation; Multi-task Evaluation; Software Testing |
✓ | Paper | Code |
| Gentopia | - | Isolated Reasoning; Multi-task Evaluation |
✓ | Paper | Code |
| EmotionBench | Human Annotation | - | ✓ | Paper | Code |
| PTB | - | Software Testing | ✓ | Paper | - |
- More papers can be found at More comprehensive Summarization.
We are maintaining an interactive table that contains more comprehensive papers related to LLM-based Agents. This table includes details such as tags, authors, publication date, and more, allowing you to sort, filter, and find the papers of interest to you.

- Lei Wang@Paitesanshi
- Chen Ma@Uily
- Xueyang Feng@XueyangFeng
If you find this survey useful, please cite our paper:
@misc{wang2023survey,
title={A Survey on Large Language Model based Autonomous Agents},
author={Lei Wang and Chen Ma and Xueyang Feng and Zeyu Zhang and Hao Yang and Jingsen Zhang and Zhiyuan Chen and Jiakai Tang and Xu Chen and Yankai Lin and Wayne Xin Zhao and Zhewei Wei and Ji-Rong Wen},
year={2023},
eprint={2308.11432},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
If you have a paper or are aware of relevant research that should be incorporated, please contribute via pull requests, issues, email, or other suitable methods.
We thank the following people for their valuable suggestions and contributions to this survey:
- Yifan Song@Yifan-Song793
- Qichen Zhao@Andrewzh112
- Ikko E. Ashimine@eltociear
If you have any questions or suggestions, please contact us via: