Train Custom Data Tutorial ⭐
glenn-jocher opened this issue · 212 comments
📚 This guide explains how to train your own custom dataset with YOLOv5 🚀. See YOLOv5 Docs for additional details. UPDATED 13 April 2023.
Before You Start
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7. Models and datasets download automatically from the latest YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installTrain On Custom Data

Creating a custom model to detect your objects is an iterative process of collecting and organizing images, labeling your objects of interest, training a model, deploying it into the wild to make predictions, and then using that deployed model to collect examples of edge cases to repeat and improve.
1. Create Dataset
YOLOv5 models must be trained on labelled data in order to learn classes of objects in that data. There are two options for creating your dataset before you start training:
Use Roboflow to create your dataset in YOLO format ⭐
1.1 Collect Images
Your model will learn by example. Training on images similar to the ones it will see in the wild is of the utmost importance. Ideally, you will collect a wide variety of images from the same configuration (camera, angle, lighting, etc.) as you will ultimately deploy your project.
If this is not possible, you can start from a public dataset to train your initial model and then sample images from the wild during inference to improve your dataset and model iteratively.
1.2 Create Labels
Once you have collected images, you will need to annotate the objects of interest to create a ground truth for your model to learn from.
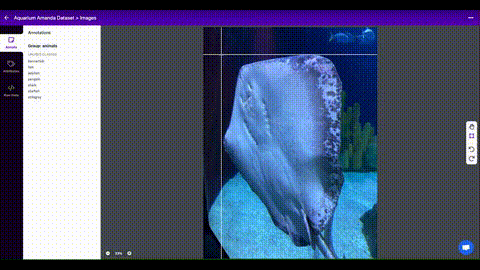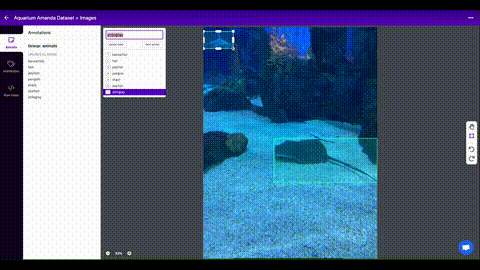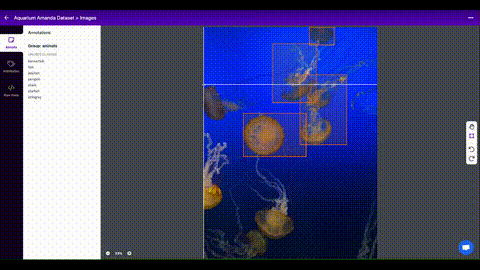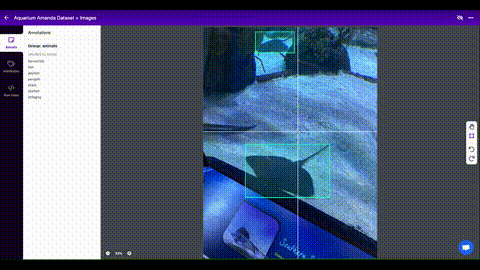
Roboflow Annotate is a simple
web-based tool for managing and labeling your images with your team and exporting
them in YOLOv5's annotation format.
1.3 Prepare Dataset for YOLOv5
Whether you label your images with Roboflow or not, you can use it to convert your dataset into YOLO format, create a YOLOv5 YAML configuration file, and host it for importing into your training script.
Create a free Roboflow account
and upload your dataset to a Public workspace, label any unannotated images,
then generate and export a version of your dataset in YOLOv5 Pytorch format.
Note: YOLOv5 does online augmentation during training, so we do not recommend
applying any augmentation steps in Roboflow for training with YOLOv5. But we
recommend applying the following preprocessing steps:

- Auto-Orient - to strip EXIF orientation from your images.
- Resize (Stretch) - to the square input size of your model (640x640 is the YOLOv5 default).
Generating a version will give you a point in time snapshot of your dataset so
you can always go back and compare your future model training runs against it,
even if you add more images or change its configuration later.

Export in YOLOv5 Pytorch format, then copy the snippet into your training
script or notebook to download your dataset.

Now continue with 2. Select a Model.
Or manually prepare your dataset
1.1 Create dataset.yaml
COCO128 is an example small tutorial dataset composed of the first 128 images in COCO train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. data/coco128.yaml, shown below, is the dataset config file that defines 1) the dataset root directory path and relative paths to train / val / test image directories (or *.txt files with image paths) and 2) a class names dictionary:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
...
77: teddy bear
78: hair drier
79: toothbrush1.2 Create Labels
After using an annotation tool to label your images, export your labels to YOLO format, with one *.txt file per image (if no objects in image, no *.txt file is required). The *.txt file specifications are:
- One row per object
- Each row is
class x_center y_center width heightformat. - Box coordinates must be in normalized xywh format (from 0 - 1). If your boxes are in pixels, divide
x_centerandwidthby image width, andy_centerandheightby image height. - Class numbers are zero-indexed (start from 0).

The label file corresponding to the above image contains 2 persons (class 0) and a tie (class 27):

1.3 Organize Directories
Organize your train and val images and labels according to the example below. YOLOv5 assumes /coco128 is inside a /datasets directory next to the /yolov5 directory. YOLOv5 locates labels automatically for each image by replacing the last instance of /images/ in each image path with /labels/. For example:
../datasets/coco128/images/im0.jpg # image
../datasets/coco128/labels/im0.txt # label
2. Select a Model
Select a pretrained model to start training from. Here we select YOLOv5s, the second-smallest and fastest model available. See our README table for a full comparison of all models.

3. Train
Train a YOLOv5s model on COCO128 by specifying dataset, batch-size, image size and either pretrained --weights yolov5s.pt (recommended), or randomly initialized --weights '' --cfg yolov5s.yaml (not recommended). Pretrained weights are auto-downloaded from the latest YOLOv5 release.
# Train YOLOv5s on COCO128 for 3 epochs
$ python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt💡 ProTip: Add --cache ram or --cache disk to speed up training (requires significant RAM/disk resources).
💡 ProTip: Always train from a local dataset. Mounted or network drives like Google Drive will be very slow.
All training results are saved to runs/train/ with incrementing run directories, i.e. runs/train/exp2, runs/train/exp3 etc. For more details see the Training section of our tutorial notebook.

4. Visualize
Comet Logging and Visualization 🌟 NEW
Comet is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with Comet Custom Panels! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
Getting started is easy:
pip install comet_ml # 1. install
export COMET_API_KEY=<Your API Key> # 2. paste API key
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. trainTo learn more about all of the supported Comet features for this integration, check out the Comet Tutorial. If you'd like to learn more about Comet, head over to our documentation. Get started by trying out the Comet Colab Notebook:
ClearML Logging and Automation 🌟 NEW
ClearML is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:
pip install clearml- run
clearml-initto connect to a ClearML server (deploy your own open-source server here, or use our free hosted server here)
You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).
You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the ClearML Tutorial for details!

Local Logging
Training results are automatically logged with Tensorboard and CSV loggers to runs/train, with a new experiment directory created for each new training as runs/train/exp2, runs/train/exp3, etc.
This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.

Results file results.csv is updated after each epoch, and then plotted as results.png (below) after training completes. You can also plot any results.csv file manually:
from utils.plots import plot_results
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
Next Steps
Once your model is trained you can use your best checkpoint best.pt to:
- Run CLI or Python inference on new images and videos
- Validate accuracy on train, val and test splits
- Export to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
- Evolve hyperparameters to improve performance
- Improve your model by sampling real-world images and adding them to your dataset
Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide

Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
I used a my_training.txt file that includes a list of training images instead of a path to the folder of images and annotations, but it always returns AssertionError: No images found in /path_to_my_txt_file/my_training.txt. Could anyone kindly give some pointers to where it went wrong? Thanks
I get the same error @shenglih
hey @glenn-jocher can i train a model on images with size 450x600??
@justAyaan sure, just use --img 600, it will automatically use the nearest correct stride multiple.
@glenn-jocher
ok.. will try.. just one doubt.. is the value of xcenter = (x + w)/ 2
OR is it x + w/2??
x_center is the center of your object in the x dimension
I used Yolov5 training on Kaggel kernel, and this error occurred. I am a novice. How can I solve this problem
Apex recommended for faster mixed precision training: https://github.com/NVIDIA/apex
Using CUDA device0 _CudaDeviceProperties(name='Tesla P100-PCIE-16GB', total_memory=16280MB)
Namespace(batch_size=4, bucket='', cache_images=False, cfg='/kaggle/input/yolov5aconfig/yolov5x.yaml', data='/kaggle/input/yolov5aconfig/wheat0.yaml', device='', epochs=15, evolve=False, hyp='', img_size=[1024, 1024], local_rank=-1, multi_scale=False, name='yolov5x_fold0', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=4, weights='', world_size=1)
Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/
2020-08-01 04:17:02.964977: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
Hyperparameters {'optimizer': 'SGD', 'lr0': 0.01, 'momentum': 0.937, 'weight_decay': 0.0005, 'giou': 0.05, 'cls': 0.5, 'cls_pw': 1.0, 'obj': 1.0, 'obj_pw': 1.0, 'iou_t': 0.2, 'anchor_t': 4.0, 'fl_gamma': 0.0, 'hsv_h': 0.015, 'hsv_s': 0.7, 'hsv_v': 0.4, 'degrees': 0.0, 'translate': 0.0, 'scale': 0.5, 'shear': 0.0}
from n params module arguments
0 -1 1 8800 models.common.Focus [3, 80, 3]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 1 315680 models.common.BottleneckCSP [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 1 3311680 models.common.BottleneckCSP [320, 320, 12]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 1 13228160 models.common.BottleneckCSP [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 1 4099840 models.common.SPP [1280, 1280, [5, 9, 13]]
9 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 5435520 models.common.BottleneckCSP [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 1360960 models.common.BottleneckCSP [640, 320, 4, False]
18 -1 1 5778 torch.nn.modules.conv.Conv2d [320, 18, 1, 1]
19 -2 1 922240 models.common.Conv [320, 320, 3, 2]
20 [-1, 14] 1 0 models.common.Concat [1]
21 -1 1 5025920 models.common.BottleneckCSP [640, 640, 4, False]
22 -1 1 11538 torch.nn.modules.conv.Conv2d [640, 18, 1, 1]
23 -2 1 3687680 models.common.Conv [640, 640, 3, 2]
24 [-1, 10] 1 0 models.common.Concat [1]
25 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
26 -1 1 23058 torch.nn.modules.conv.Conv2d [1280, 18, 1, 1]
27 [] 1 0 models.yolo.Detect [1, [[116, 90, 156, 198, 373, 326], [30, 61, 62, 45, 59, 119], [10, 13, 16, 30, 33, 23]], []]
Traceback (most recent call last):
File "/kaggle/input/yolov5/yolov5-master/train.py", line 469, in
train(hyp, tb_writer, opt, device)
File "/kaggle/input/yolov5/yolov5-master/train.py", line 80, in train
model = Model(opt.cfg, nc=nc).to(device)
File "/kaggle/input/yolov5/yolov5-master/models/yolo.py", line 70, in init
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
File "/kaggle/input/yolov5/yolov5-master/models/yolo.py", line 100, in forward
return self.forward_once(x, profile) # single-scale inference, train
File "/kaggle/input/yolov5/yolov5-master/models/yolo.py", line 120, in forward_once
x = m(x) # run
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in call
result = self.forward(*input, **kwargs)
File "/kaggle/input/yolov5/yolov5-master/models/yolo.py", line 27, in forward
x[i] = self.mi # conv
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/container.py", line 147, in getitem
return self._modules[self._get_abs_string_index(idx)]
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/container.py", line 137, in _get_abs_string_index
raise IndexError('index {} is out of range'.format(idx))
IndexError: index 0 is out of range
This is old code. Suggest you git clone the latest. PyTorch 1.6 is a requirement now.
@glenn-jocher yolov5 is really flexible for training on custom datasets! could you please share the script for processing and converting coco to the train2017.txt file? I already have this file but would like to regenerate it with some modifications.
Hi, I have a newbie question...
Could you explain what the difference between providing pretrained weights vs not? when to use?
- Start training from pretrained --weights yolov5s.pt, or from randomly initialized --weights '' *
Should I expect better results if I use yolov5s.pt as pretrained weights?
Thanks
@rwin94 for small datasets or for quick results yes always start from the pretrained weights:
python train.py --cfg yolov5s.yaml --weights yolov5s.pt
You can see a comparison of pretrained vs from scratch in the custom data training turorial:
https://docs.ultralytics.com/yolov5/tutorials/train_custom_data#6-visualize
I want to ask a question: it showes
File "/content/yolov5/utils/datasets.py", line 344, in <listcomp> labels, shapes = zip(*[cache[x] for x in self.img_files]) KeyError: '../dota_data/images/val/P0800__1__552___0.png
when training in Google colab.
But everything is ok in my own laptop, so it cannot train with .png?
Hello, I'd like to ask you something. "If no objects in image.no *. txt file is required". For images without labels in the training data (there is no target inthe image), how does it participate in the training as a negative sample?
@liumingjune all images are treated equally during training, irrespective of the labels they may or may not have.
Thanks your reply. I have a question after looking at the code. I would like to ask if you only keep the latest and best models which under runs file when you save the training model? Can't you save the model under the specified epoch? Is it ok to choose the latest model directly after the training? How to select other models under the epoch if this optimal detection does not work well?
@liumingjune best.pt and last.pt are saved, which are the best performing model across all epochs and the most recent epoch's model. You can customize checkpointing logic here:
Lines 333 to 348 in 9ae8683
Hello, thank you for your reply. I want to know if Yolov5 has done any work on small target detection.
@liumingjune yes, of course. All models will work well with small objects without any changes. My only recommendation is to train at the largest --img-size you can, up to native resolution.
We do have custom small object models with extra ops targeted to higher resolution layers (P2 and P3) which we have not open sourced. These custom models outperform our official models on COCO, in particular in the small object class, but also come with a speed penalty, so we decided not to release them to the community at the present time.
@liumingjune all images are treated equally during training, irrespective of the labels they may or may not have.
Hello, I have a question. My test results showed a high false alarm rate. If I want to add some large images with no target and only background as negative samples to participate in the training. Obviously, in the format you requested, these images are not labled with *.txt. I have lots of big images with no targets here. so do you have any suggestions for the number of large images with no targets? I am concerned that the imbalance in the number of positive and negative samples will affect the effectiveness of training.Wish your reply.Thanks!
Hello, I have a question. My test results showed a high false alarm rate. If I want to add some large images with no target and only background as negative samples to participate in the training. Obviously, in the format you requested, these images are not labled with *.txt. I have lots of big images with no targets here. so do you have any suggestions for the number of large images with no targets? I am concerned that the imbalance in the number of positive and negative samples will affect the effectiveness of training.Wish your reply.Thanks!
@liumingjune I can't advise you on custom dataset training.
@liumingjune I can't advise you on custom dataset training.
Thanks. I understand. I just want to find out if the ratio of positive and negative samples(number of image has label and has no label) has any effect on training.
I want to ask a question: it showes
File "/content/yolov5/utils/datasets.py", line 344, in <listcomp> labels, shapes = zip(*[cache[x] for x in self.img_files]) KeyError: '../dota_data/images/val/P0800__1__552___0.png
when training in Google colab.But everything is ok in my own laptop, so it cannot train with .png?
delete *.cache file, again run python3 train.py
I want to ask a question: it showes
File "/content/yolov5/utils/datasets.py", line 344, in <listcomp> labels, shapes = zip(*[cache[x] for x in self.img_files]) KeyError: '../dota_data/images/val/P0800__1__552___0.png
when training in Google colab.
But everything is ok in my own laptop, so it cannot train with .png?delete *.cache file, again run python3 train.py
Thanks!!
Hi, I am a very beginner in Yolo v5 but I learned it quickly to detect mangoes from digital images with appreciable accuracy. Many thanks to @glenn-jocher for the great contribution.
I am stuck here to find out how to plot the mAP & Loss vs the number of iterations curve just as in Yolov4. Also after training the model any possibility to get the False positives and False Negatives count?
Thanks in advance for the support.
Regards
Pavan
@liumingjune as I said before all images are treated equally during training, irrespective of the labels they may or may not have.
@liumingjune yes of course, every image participates in loss computation equally. Objectness loss is evaluated for every point in the output grid, giou and cls loss are evaluated for positive object labels.
I want to ask a question: it showes
File "/content/yolov5/utils/datasets.py", line 344, in <listcomp> labels, shapes = zip(*[cache[x] for x in self.img_files]) KeyError: '../dota_data/images/val/P0800__1__552___0.png
when training in Google colab.But everything is ok in my own laptop, so it cannot train with .png?
same problem. Have you solved it?
@lyuweiwang @lyuweiwang all of the most common formats are supported for training (images) and inference (images and videos):
Lines 20 to 22 in ffe9eb4
@glenn-jocher can we train yolov5 on a dataset which has varying image sizes?
Ex:-
Img 1 - 256*400
Img 2 - 300*300
@justAyaan suggest you run the tutorial and observe the coco128 dataset.
Hello, I have a question. I want to use hyperparameters in yolov5.but i don't know how to use it . i want to use mixup in training my data. how should i set the mixup
Thanks in advance for the support.
@Alex-afka two hyp files are available in data/. To use mixup for example, set the mixup probability 1 > mixup > 0 in your hyp file:
Line 29 in c8e5181
@glenn-jocher
I meant this:-
can we train yolov5 on a dataset which has varying image sizes?
Ex:-
Img 1 - 256*400
Img 2 - 300*300
@justAyaan yes, you can train on datasets with any image sizes.
@glenn-jocher so what is going to be the specified --img-size for this kind of a scenario?
@justAyaan I can't advise you on custom training. Experiment if you want to understand the effects of a variable on your results.
Thanks for the great work.
I'm training the model with default --img-size 640. Then i can see the following

But when i train by using a higher image size --img-size 1024 , couldn't see the k-means for custom anchor generation and new anchor generated model. Does it meant that no new kmeans custom anchor generation with this higher --img-size ?

@Samjith888 autoanchor only runs when the best possible recall is under threshold, so in your second example it's judged that at img size 1024 the best possible recall is sufficiently high to use the default anchors rather than computing new anchors.
I have very small objects in the dataset, is there anything else should i add for small object detection ?
--single-cls ,--rect , --evolve and --hyp
I couldn't find a detailed information about above flags, please explain..
When I use yolov5 to train a custom data set, I have modified the nc value of my yaml file and the nc value of yolov5s.yaml file, but it keeps returning AssertionError: Label class 2 exceeds nc=2 in /content/Garbage_data/Garbage.yaml. Possible class labels are 0-1,Hope to get your reply
@mml438659613 as the message states, your dataset has two classes, and your labels can only show class 0 or 1. You have incorrect labels outside of this permitted range.
Hello, I'm using yolov5 on custom data set of dimension 1352*760, should I use the --rect option ?
Also when I train my model the precision and the recall stay at 0, do you have an explanation for this ?
My objects are very small, you can see below

@constantinfite train using all default settings and check your jpgs as stated in the tutorial.
@glenn-jocher
my command for training is
!python train.py --img 640 --batch 16 --epochs 5 --data ./data.yaml --cfg ./models/yolov5s.yaml --weights ''
The organization of my folder

My data.yaml file located in yolov5 folder

@constantinfite train at least 300 epochs, or 1000 epochs if you don't see results after 300.
I run this tutorial, but there is no prediction in the test_batch0_pred.jpg. Could anyone kindly give some pointers to where it went wrong? Thanks

@xcz0 you need to fully train (to 300 epochs) and then examine your predictions.
Hi @glenn-jocher, Hi fellows,
Here is a very quick question. I've built my datasets (train, valid and test) following the requirement: locate 'images' and 'labels' folders next to each other such as:
dataset/images/train/1.jpg # image
dataset/labels/train/1.txt # label
Within the .yaml file, it is specified this:
"# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]"
But I can't see (or I don't understand) the specifications related to the labels.txt path.
So, this "train: [path1/images/, path2/images/]" should be "train: [path1/images/, path2/labels/]"?
To sum up, how should we specify both the images and labels paths for the train, for example?
Cheers ✌️
UPDATE:
Well, I actually it seems that train.py scans the 'datasets/labels/train' folder, so no need to specify the label path. If I got it well.
@MikeHatchi that is correct, there is only 1 degree of freedom here, so only 1 piece of information is required (the second, the labels, are a function of the first, the images).
i will train custom dataset but i have this error
TypeError: float() argument must be a string or a number, not 'tuple'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "train.py", line 460, in
train(hyp, opt, device, tb_writer)
File "train.py", line 167, in train
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 53, in create_dataloader
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 380, in init
self.shapes = np.array(shapes, dtype=np.float64)
ValueError: setting an array element with a sequence.
Traceback (most recent call last):
File "/home/amkhc2s/data/anaconda/envs/ultralytics/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/amkhc2s/data/anaconda/envs/ultralytics/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/amkhc2s/data/anaconda/envs/ultralytics/lib/python3.8/site-packages/torch/distributed/launch.py", line 261, in
main()
File "/home/amkhc2s/data/anaconda/envs/ultralytics/lib/python3.8/site-packages/torch/distributed/launch.py", line 256, in main
raise subprocess.CalledProcessError(returncode=process.returncode,
subprocess.CalledProcessError: Command '['/home/amkhc2s/data/anaconda/envs/ultralytics/bin/python', '-u', 'train.py', '--local_rank=3', '--batch-size', '256', '--data', '/home/amkhc2s/data/yolov5/data/xray.yaml', '--cfg', '/home/amkhc2s/data/yolov5/models/yolov5x.yaml', '--weights', '/home/amkhc2s/data/yolov5/weights/yolov5x.pt']' returned non-zero exit status 1.
@MakAbdel it appears you may have environment issues. Please ensure you meet all dependency requirements if you are attempting to run YOLOv5 locally. If in doubt, create a new virtual Python 3.8 environment, clone the latest repo (code changes daily), and pip install -r requirements.txt again. We also highly recommend using one of our verified environments below.
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.6. To install run:
$ pip install -r requirements.txtEnvironments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Google Colab Notebook with free GPU:
- Kaggle Notebook with free GPU: https://www.kaggle.com/ultralytics/yolov5
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Docker Image https://hub.docker.com/r/ultralytics/yolov5. See Docker Quickstart Guide
Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are passing. These tests evaluate proper operation of basic YOLOv5 functionality, including training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu.
the yaml has both a 'train' and 'val' field, in the tutorial they point to the same directory. Is it recommended to do this, or should we take some subset of our training data and place them into a 'val' directory?
@gltovar you should follow standard practices for dataset division. The tutorial shows how to overfit your train set to prove your pipeline works.
@glenn-jocher I tested with coco128 and only one GPU locally and it worked. but for my dataset with only one GPU I received this error message:
TypeError: float() argument must be a string or a number, not 'tuple'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "train.py", line 460, in
train(hyp, opt, device, tb_writer)
File "train.py", line 167, in train
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 53, in create_dataloader
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 380, in init
self.shapes = np.array(shapes, dtype=np.float64)
ValueError: setting an array element with a sequence.
@MakAbdel well, if training works with coco128 but not your dataset, then there is a problem in your dataset somewhere. Follow all of the directions above and try to debug the issue.
@glenn-jocher I changed the location of the dataset but I received this error message:
Transferred 794/802 items from /home/amkhc2s/data/yolov5/weights/yolov5x.pt Optimizer groups: 134 .bias, 142 conv.weight, 131 other Traceback (most recent call last): File "train.py", line 460, in <module> train(hyp, opt, device, tb_writer) File "train.py", line 167, in train dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt, File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 53, in create_dataloader dataset = LoadImagesAndLabels(path, imgsz, batch_size, File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 379, in __init__ labels, shapes = zip(*[cache[x] for x in self.img_files]) File "/home/amkhc2s/data/yolov5/utils/datasets.py", line 379, in <listcomp> labels, shapes = zip(*[cache[x] for x in self.img_files]) KeyError: '../dataset/images/train/023019.jpg'
@glenn-jocher, Hello!
This is all new to me.
How can I train a new class? Should new data be fully labeled?
For example, I need to identify person and face masks. I have a tagged dataset for masked people (only face masks). Do I need to label persons on them?
If you do as in the manual, then the model detects masks well, but stops detecting people. What am I doing wrong?
Do I need a dataset in which all possible classes are labeled on each image?
@ptz-nerf your model will be trained on all classes in your dataset.
@glenn-jocher Hi, is the number of images in the dataset (18.000 images) can generate this type of error ?
Traceback (most recent call last): File "train.py", line 460, in train(hyp, opt, device, tb_writer) File "train.py", line 167, in train dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt, File "../data/yolov5/utils/datasets.py", line 53, in create_dataloader dataset = LoadImagesAndLabels(path, imgsz, batch_size, File "../data/yolov5/utils/datasets.py", line 380, in init self.shapes = np.array(shapes, dtype=np.float64) ValueError: setting an array element with a sequence.
I tried with half the dataset and it worked
@MakAbdel that's odd. I've seen a few bug reports with the same ValueError: setting an array element with a sequence #1139. If you reduced your dataset size it may be due to an image in the removed portion, or the .cache files, which are deleted and recreated on dataset modification #958 (comment). Can you retry with the full 18k images and see if it persists?
If not can you reproduce this in a Colab notebook and link us to it?
@ptz-nerf your model will be trained on all classes in your dataset.
@glenn-jocher , thanks! But something else confuses me.
I have one part of the dataset with labeled persons (from COCO), another part with people with masks, but the people themselves are not labeled there, but only the masks. Wouldn't that be a problem? Or is it necessary to mark persons there?
After training persons are no longer detected with that dataset.
@ptz-nerf all objects corresponding to your classes must be fully labelled throughout your entire dataset.
I chose the simpler way of replacing the train folder with my own images and ran the "train.py" without the default weights - hoping it will build them basis my data set. More importantly i updated the "person" that it identifies to a few sub categories - such as "security" and "swiggy" etc. However, the output continues to id them only as "person". I did bring down the threshold to see if it is lower probability that's hurting but still no luck. Any suggestions?
and first of all - big thanks for a faster version here. Works very well otherwise on default data sets and mp4.
and my coco128 yaml looks like this now - with my added labels. Hope that's alright as well. Pls check last line where i've added 9 more labels.
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush', 'security', 'swiggy','scooter', 'carEXIT', 'carENTRY', 'cyclist', 'bike', 'sweeps', 'LPG']
Couple of additional data points ...
- I realized that i didn't use the weights coming from this "train.py" call explicitly so i copied the best.pt and last.pt on to the main folder and tried this -
python detect.py --source inference/images --weights best.pt --conf 0.25
No luck but maybe the 48 odd images i added weren't sufficient; but good thing the old bounding boxes with the old tags for Person/ Car etc. have also not come through. - I also have to mention that i edited each of the labelimg files to make sure the indices for the added labels were appropriate. Something like -
81 0.480208 0.319907 0.058333 0.234259
81 0.553646 0.327315 0.036458 0.213889
81 0.385937 0.265741 0.030208 0.150000
82 0.492188 0.305093 0.042708 0.199074
I thought this could've been a problem given that the indices were originally starting from 0. No luck with that either.
Some good news ... i realized the last folder in the "runs" does have images that have recognized 81, 82, ... 87. For some reason while i run detect.py again - either their probability is not good enough or I don't know which .pt to use. Kindly I've tried best.pt or the last.pt coming from the runs latest folder but no luck. The only proof of recognition is in the images within the runs folder but not when i run detect again.
@glenn-jocher ... could you pls advise.
thanks.
@glenn-jocher - kindly let me know if you had a chance to look at my configuration above. Either my training data set is not clear and significant enough or am missing something here. Kindly advise.
thanks.
@hungthanhpham94 see https://en.wikipedia.org/wiki/Training,_validation,_and_test_sets
@glenn-jocher for custom data training by yolov5, what‘s the hyp pattern that finetune or from scratch can get the better result?
@nanhui69 depends on your dataset.
@glenn-jocher waht's meanning? my dataset has 2w images and 10 category now, BTW could you give a example??
While training on a custom dataset with one class by using yolov5l.yaml model, i have created a data/custom.yaml and added following lines into it
custom.yaml
train: train path
val: val path
nc: 1
names: ['cat']
Added this custom.yaml file into the train command, but while doing inference with the generated weight , the detected class_name is displaying as "item 0.x%". Should i change the number classes and names in any other files !! Didn't found anything regarding in the custom training tutorial
@Samjith888 this can occur if you force --single-cls training on a single-class dataset. --single-class forces multi-class dataset into single class mode and assigns the 'item' label to the single class. If your dataset is already single class, simply train normally.
Line 74 in 6bd5e8b
UPDATE: PR #1719 should resolve this
Is there a method to get the metrics that are calculated during training for the test set too? If i set the path to a test set in my yaml it doesnt seem to make a difference since the metrics are still getting calculated on train and val.
@glenn-jocher Thank you! Is there also a way to see the results of the model during training on the test set? So i can see on which epoch the model performs best, since i have the feeling models with shorter training time perform better on my data.
First of all, thank you guys so much for making YOLO so accessible, and for taking the time to make this awesome tutorial!
However, I was also hoping I might get some assistance on this thread. I cannot for the life of me figure out what is meant by non-positive stride is not supported when trying to use my custom dataset, formatted with the help of roboflow.com's free tier.
I've re-read both tutorials one thousand times and must be missing something stupid. If anyone can point me in the right direction, it would be very much appreciated, as Google doesn't seem to be very helpful when searching for "non-positive stride not is not supported".
You can find the failing Colab notebook here.
Here's the command I'm using:
python yolov5/train.py --img 415 --batch 2 --epochs 100 --data './data.yaml' --cfg "./custom_yolov5s.yaml" --weights '' --name yolov5s_results
And here's what YOLO is telling me:
(yolotest) ➜ yolov5 git:(master) ✗ python train.py --img 415 --batch 2 --epochs 100 --data './data.yaml' --cfg "./custom_yolov5s.yaml" --weights '' --name yolov5s_results
Using torch 1.7.1 CPU
Namespace(adam=False, batch_size=2, bucket='', cache_images=False, cfg='./custom_yolov5s.yaml', data='./data.yaml', device='', epochs=100, evolve=False, exist_ok=False, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[415, 415], local_rank=-1, log_artifacts=False, log_imgs=16, multi_scale=False, name='yolov5s_results', noautoanchor=False, nosave=False, notest=False, project='runs/train', rect=False, resume=False, save_dir='runs/train/yolov5s_results', single_cls=False, sync_bn=False, total_batch_size=2, weights='', workers=8, world_size=1)
Start Tensorboard with "tensorboard --logdir runs/train", view at http://localhost:6006/
Hyperparameters {'lr0': 0.01, 'lrf': 0.2, 'momentum': 0.937, 'weight_decay': 0.0005, 'warmup_epochs': 3.0, 'warmup_momentum': 0.8, 'warmup_bias_lr': 0.1, 'box': 0.05, 'cls': 0.5, 'cls_pw': 1.0, 'obj': 1.0, 'obj_pw': 1.0, 'iou_t': 0.2, 'anchor_t': 4.0, 'fl_gamma': 0.0, 'hsv_h': 0.015, 'hsv_s': 0.7, 'hsv_v': 0.4, 'degrees': 0.0, 'translate': 0.1, 'scale': 0.5, 'shear': 0.0, 'perspective': 0.0, 'flipud': 0.0, 'fliplr': 0.5, 'mosaic': 1.0, 'mixup': 0.0}
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 20672 models.common.Bottleneck [64, 64]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 1 161152 models.common.BottleneckCSP [128, 128, 3]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 1 641792 models.common.BottleneckCSP [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
9 -1 1 1905152 models.common.BottleneckCSP [512, 512, 2]
10 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
11 -1 1 25 torch.nn.modules.conv.Conv2d [24, 1, 1, 0]
12 -2 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
13 [-1, 6] 1 0 models.common.Concat [1]
14 -1 1 197120 models.common.Conv [768, 256, 1, 1]
15 -1 1 313088 models.common.BottleneckCSP [256, 256, 1, False]
16 -1 1 25 torch.nn.modules.conv.Conv2d [24, 1, 1, 0]
17 -2 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
18 [-1, 4] 1 0 models.common.Concat [1]
19 -1 1 49408 models.common.Conv [384, 128, 1, 1]
20 -1 1 78720 models.common.BottleneckCSP [128, 128, 1, False]
21 -1 1 25 torch.nn.modules.conv.Conv2d [24, 1, 1, 0]
22 [] 1 0 models.yolo.Detect [3, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], []]
Traceback (most recent call last):
File "train.py", line 512, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "train.py", line 93, in train
model = Model(opt.cfg, ch=3, nc=nc).to(device) # create
File "/Users/nbaughman/PycharmProjects/yolotest/yolov5/models/yolo.py", line 93, in __init__
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
File "/Users/nbaughman/PycharmProjects/yolotest/yolov5/models/yolo.py", line 123, in forward
return self.forward_once(x, profile) # single-scale inference, train
File "/Users/nbaughman/PycharmProjects/yolotest/yolov5/models/yolo.py", line 139, in forward_once
x = m(x) # run
File "/usr/local/anaconda3/envs/yolotest/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/anaconda3/envs/yolotest/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 423, in forward
return self._conv_forward(input, self.weight)
File "/usr/local/anaconda3/envs/yolotest/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 419, in _conv_forward
return F.conv2d(input, weight, self.bias, self.stride,
RuntimeError: non-positive stride is not supported
I'm using a fresh Conda Python 3.8 environment and installed the requirements from the YOLO repo that I cloned, so I wouldn't think it would be an incompatibility with modules. I'm figured maybe it had to do with my image sizes (which roboflow has cropped to 415x415, but even when I use other datasets with different resolutions I get the same thing.
I've also tried changing the batch size and epoch count (unsurprisingly, this had no effect).
Any links to where I can read more about this problem would be helpful! I feel like I'm just missing something easy...
EDIT
I have also just tried this under a virtuelenv venv running Python 3.9 with the same result.
Here is a link to the Colab notebook that is currently failing.
Solved(ish)
Turned out to be an issue with my custom configuration file for YOLOv5s. Does anyone know where I can go to learn more about the configuration options available?
@Kraufel You're not seeing any outputs in the run folder?
@baughmann I do. But all the metrics are calculated on the validation set. If i give my model an image that it has not seen before the performance drops heavily to the point where the model might be useless. So for me it would be cool to see how the model performs on the validation set aswell as the test set after each epoch.
@Kraufel Ahh that would be cool, apologies for the misunderstanding.
Is it possible to export your model each time it reaches an epoch and test it manually? If so, it may be possible to make an automated process to do it.
@Kraufel test sets are expressly designed not to be used during train nor to impact training. This is the purpose of a validation set. See https://en.wikipedia.org/wiki/Training,_validation,_and_test_sets
@baughmann if you believe there is a bug with the official code or models please raise a bug report issue providing a fully reproducible example with code. Thank you.
@glenn-jocher there is not at all. The only issue is with a third party tutorial. Feel free to edit my comment as necessary. However, my comment may help those who use the same flawed tutorial in the future and try to Google the issue.
@baughmann ok got it. Yes unfortunately we can't control the 3rd party implementations built on YOLOv5, and its possible that updates here may inadvertently break downstream libraries running on master. In this case you might try cloning the latest stable release rather than the current master branch:
git clone https://github.com/ultralytics/yolov5 -b v3.1@glenn-jocher I understand the roles of the different sets. But i have trained a model under the same circunstances for 10 and 50 epochs. The 10-epoch-model was doing a lot better on my test data then the 50-epoch-model. Maybe the model is overfitting but it wont show it in train and val set during training. And since I only want the performance of the model on the test set plottet during the training to see if it really overfits it would not affect the training in any way right?
@Kraufel from your description your dataset and training methodology lack generalization capability, which is separate from allowing your test set to influence training, which is prohibited practice under in all ML disciplines.
@Kraufel the solution to poor generalization is to increase the quantity and diversity of your dataset, and to better align your train and val sets with your test set.

Thank you! Will try to work on my dataset!
Hello @glenn-jocher ,
Is there approximate time constraints for training coco128 dataset on hardware GeForce GTX 860M, 2048.0MB with PyTorch implementation?
I have an issue with training of my custom dataset (stride issue or just hangs out) and start search of the root cause. I verified all requirements and check training on your test target dataset coco128. detect.py works fine, the issue is with train.py
!python train.py --batch 16 --img 640 \
--epochs 5 \
--data data\coco128.yaml \
--weights yolov5s.pt
There is no any console output at the start (it might be ok as detect.py launch also produced logs only when had finished execution) and it is run for a while without any result. Here there was complain the model training takes enough time which push me to give !python train.py more time.
At this moment I would like to clarify expected behaviour, is possible to turn on logs in runtime and what might be possible issue with this run.
@Gelassen recommend Colab notebook for getting started training in just two clicks, you can see reference speeds there as well.
@glenn-jocher I checked it, Colab works on powerful hardware that is not common for desktop PC - not sure is it ok to divide by ten to get speed close to my case. Anyway, I would like to continue work locally, not in the cloud, and currently I follow your checklist to verify where is the issue when train my custom dataset.
@Gelassen , i've had similar issues in the past. You could try one of the following -
reduce batch size
make sure your cuda libraries are used up appropriately ... in my case i have to stick my neck out to make sure cuda10.1 is put to use (shows up in the terminal when you make the call) ... pasting the terminal output here.
2021-01-02 13:56:26.xxxxxx: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
Also use the task manager to check if your GPU is put to "use". In my case (on windows) i clearly see the memory usage shoot up close to 2 gb. The command i use is this.
python train.py --img 640 --batch 2 --epochs 5 --data coco128.yaml --weights ./yolov5s.pt --workers 0
hope this helps. If you want to further debug you can open up train.py in spyder or whatever IDE and trace through the calls. I've been trying to print the conf score from a general.py (which you will observe gets called for the util functions) for some troubleshooting :)
Hi @glenn-jocher, I have followed all you'r suggestions but I'm still having trouble with YOLOv5. I made a custom dataset with one single object per image with white background, trained it for 300 epochs as suggested with all default setting. I'm getteing great mAP and results however when running the detect.py using the trained weights and the same image_size as the training image_size on certin images the detection is not working. On images with white backgorunds the detection of objects works great, but when these objects are in a different background for example on a table, these objects are not detected. Is there any explanation for this ?
@CPor99 this is correct behavior. Your training data must encompass the entire inference space you plan on deploying the model to. Training on white backgrounds will produce a model that is only usable on white backgrounds.
@glenn-jocher , if we have to get a given coco class value to split into a few other alternatives - such as giving a name to say a motor-cycle or identify say a particular cat or a dog, is it better for us to remove the parent entry that is "cat" or "motor-cycle" and then have the new set of images qualify what we want it to be ? or do we just append to the 80 classes with these choices and of course with appropriate images? kindly share your thoughts.
@sganesh07 follow the tutorial and experiment with the alternatives available. Your dataset requires properly labelled classes for all classes you want to detect, extraneous classes add nothing.
Thanks @glenn-jocher ... i do see the labelled classes with their new indices (81, 82 etc.) on the "runs" folder but when I used the best or last.pt from the same for the subsequent "detect.py" call the new label wasn't coming up. I thought it could be with the conf value so i kept lowering that. No luck yet. Maybe i need more images; right now i have about 45 of them appended to the default images. If there is anything obvious am missing kindly let me know.
thank you.
@sganesh07 best results require a significant dataset. i.e. COCO has 1M instances over 120k images with 80 classes, therefore similar performance requires roughly 10,000 instances over 1500 images per class.