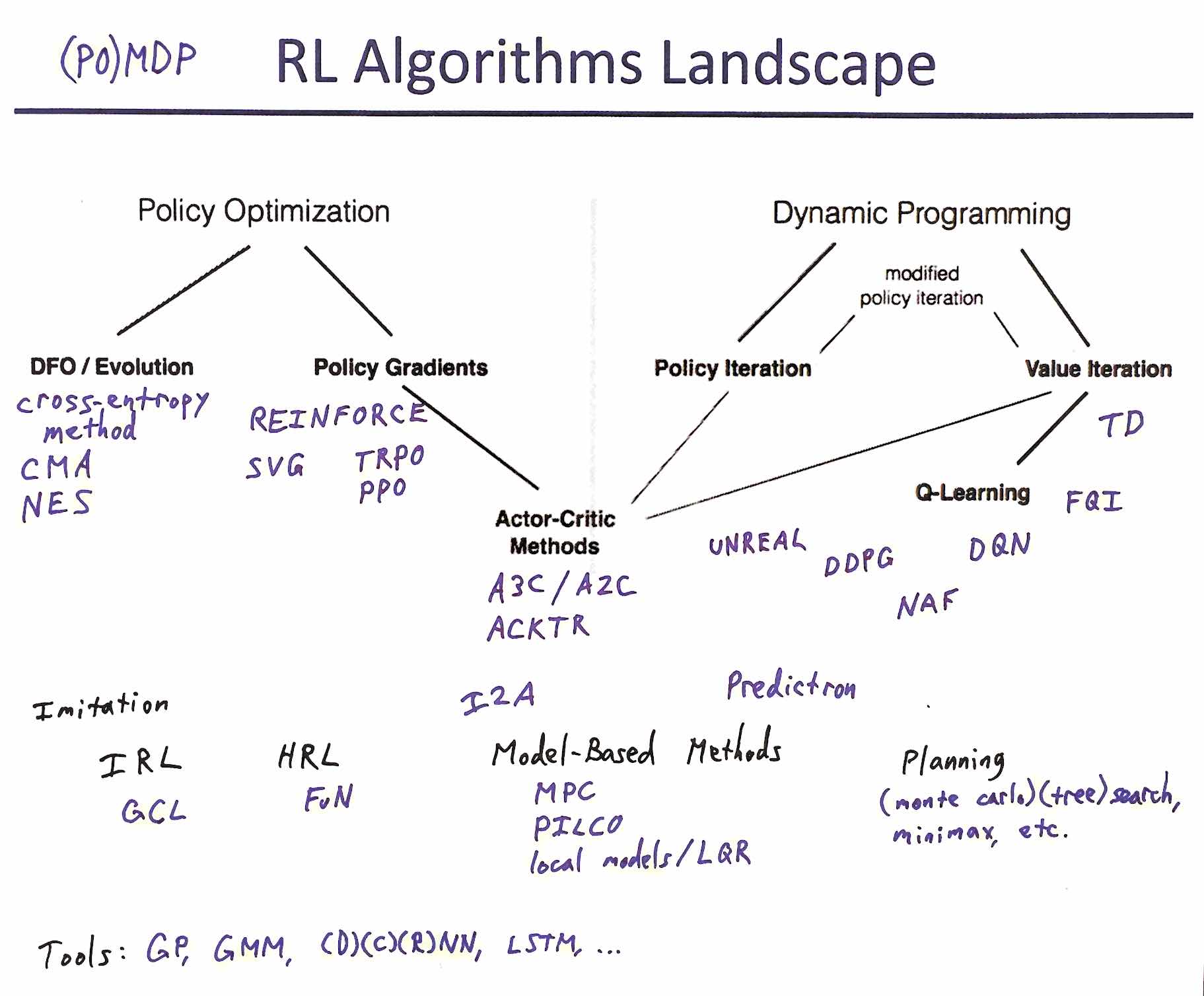
PyTorch tutorial of: actor critic / proximal policy optimization / acer / ddpg / twin dueling ddpg / soft actor critic / generative adversarial imitation learning / hindsight experience replay
The deep reinforcement learning community has made several improvements to the policy gradient algorithms. This tutorial presents latest extensions in the following order:
- Advantage Actor Critic (A2C)
- High-Dimensional Continuous Control Using Generalized Advantage Estimation
- Proximal Policy Optimization Algorithms
- Sample Efficient Actor-Critic with Experience Replay
- Continuous control with deep reinforcement learning
- Addressing Function Approximation Error in Actor-Critic Methods
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Generative Adversarial Imitation Learning
- Hindsight Experience Replay
- Remember you are not stuck unless you have spent more than a week on a single algorithm. It is perfectly normal if you do not have all the required knowledge of mathematics and CS.
- Carefully go through the paper. Try to see what is the problem the authors are solving. Understand a high-level idea of the approach, then read the code (skipping the proofs), and after go over the mathematical details and proofs.
Deep Q Learning tutorial: DQN Adventure: from Zero to State of the Art