English | 中文



- Extract data from PDF with
PyMuPDF, e.g. text, images and drawings - Parse layout with rule, e.g. sections, paragraphs, images and tables
- Generate docx with
python-docx
-
Parse and re-create page layout
- page margin
- section and column (1 or 2 columns only)
- page header and footer [TODO]
-
Parse and re-create paragraph
- OCR text [TODO]
- text in horizontal/vertical direction: from left to right, from bottom to top
- font style, e.g. font name, size, weight, italic and color
- text format, e.g. highlight, underline, strike-through
- list style [TODO]
- external hyper link
- paragraph horizontal alignment (left/right/center/justify) and vertical spacing
-
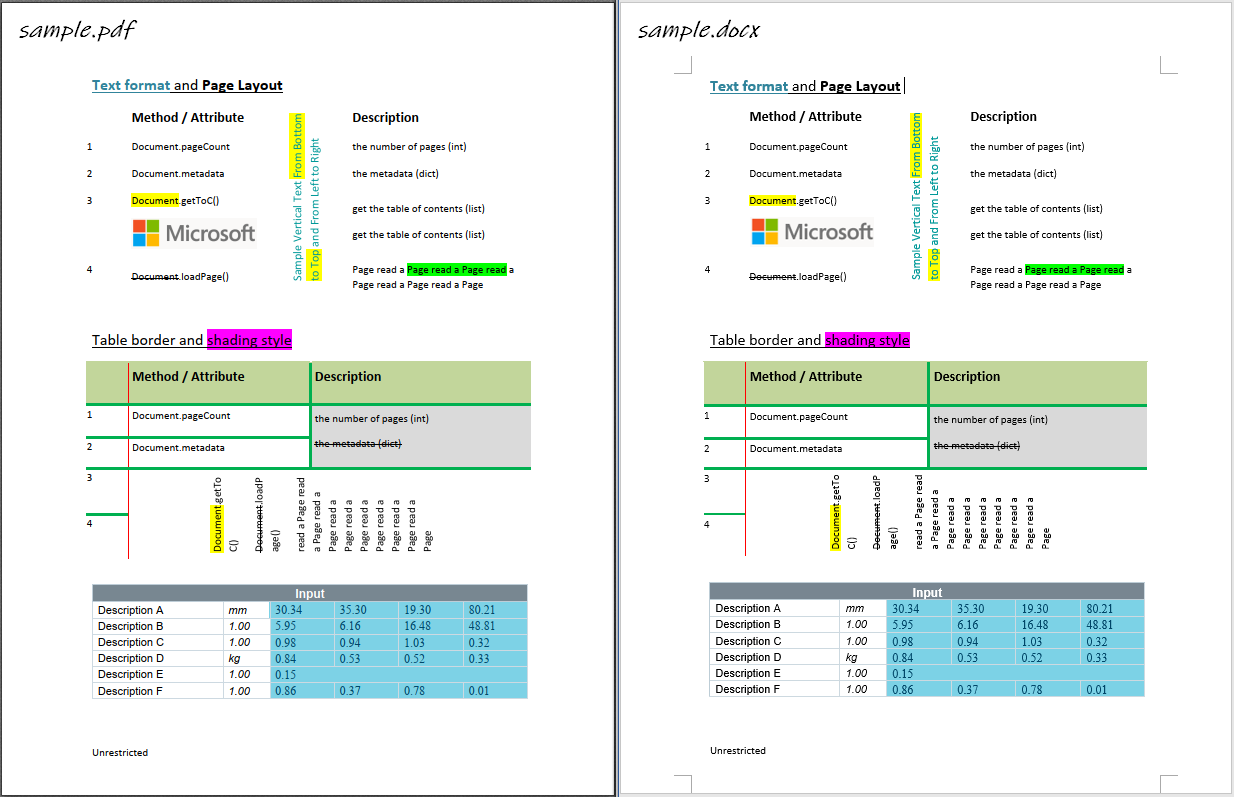
Parse and re-create image
- in-line image
- image in Gray/RGB/CMYK mode
- transparent image
- floating image, i.e. picture behind text
-
Parse and re-create table
- border style, e.g. width, color
- shading style, i.e. background color
- merged cells
- vertical direction cell
- table with partly hidden borders
- nested tables
-
Parsing pages with multi-processing
It can also be used as a tool to extract table contents since both table content and format/style is parsed.
- Text-based PDF file
- Left to right language
- Normal reading direction, no word transformation / rotation
- Rule-based method can't 100% convert the PDF layout