Welcome to the final project of the camera course. By completing all the lessons, you now have a solid understanding of keypoint detectors, descriptors, and methods to match them between successive images. Also, you know how to detect objects in an image using the YOLO deep-learning framework. And finally, you know how to associate regions in a camera image with Lidar points in 3D space. Let's take a look at our program schematic to see what we already have accomplished and what's still missing.

In this final project, you will implement the missing parts in the schematic. To do this, you will complete four major tasks:
- First, you will develop a way to match 3D objects over time by using keypoint correspondences.
- Second, you will compute the TTC based on Lidar measurements.
- You will then proceed to do the same using the camera, which requires to first associate keypoint matches to regions of interest and then to compute the TTC based on those matches.
- And lastly, you will conduct various tests with the framework. Your goal is to identify the most suitable detector/descriptor combination for TTC estimation and also to search for problems that can lead to faulty measurements by the camera or Lidar sensor. In the last course of this Nanodegree, you will learn about the Kalman filter, which is a great way to combine the two independent TTC measurements into an improved version which is much more reliable than a single sensor alone can be. But before we think about such things, let us focus on your final project in the camera course.
- cmake >= 2.8
- All OSes: click here for installation instructions
- make >= 4.1 (Linux, Mac), 3.81 (Windows)
- Linux: make is installed by default on most Linux distros
- Mac: install Xcode command line tools to get make
- Windows: Click here for installation instructions
- OpenCV >= 4.1
- This must be compiled from source using the
-D OPENCV_ENABLE_NONFREE=ONcmake flag for testing the SIFT and SURF detectors. - The OpenCV 4.1.0 source code can be found here
- This must be compiled from source using the
- gcc/g++ >= 5.4
- Linux: gcc / g++ is installed by default on most Linux distros
- Mac: same deal as make - install Xcode command line tools
- Windows: recommend using MinGW
- Clone this repo.
- Make a build directory in the top level project directory:
mkdir build && cd build - Compile:
cmake .. && make - Run it:
./3D_object_tracking.
-
Implement the method "matchBoundingBoxes", which takes as input both the previous and the current data frames and provides as output the ids of the matched regions of interest (i.e. the boxID property). Matches must be the ones with the highest number of keypoint correspondences.
In "matchBoundingBoxes" function, we iterate all of the matches between previous and current data frame, then we are able to extract corresponding key-points in both previous and current frames based on these matches. Let's assume the key-points pair is (prevKeyPoint, currKeyPoint). So when we try to match previous bounding boxes to current bounding boxes, we check if the previous bounding box contains prevKeyPoint and current bounding box contains currKeyPoint at the same time. If so, the count number of total matches between previous bounding box ID and current bounding box ID will be accumulated(+1). At the end of inner loop, we choose the match with max count number, or in other words the match has highest number of key-point correspondences, as the final match between previous and current bounding box ID. Then we keep iterating until we find all matches.
-
Compute the time-to-collision in second for all matched 3D objects using only Lidar measurements from the matched bounding boxes between current and previous frame.
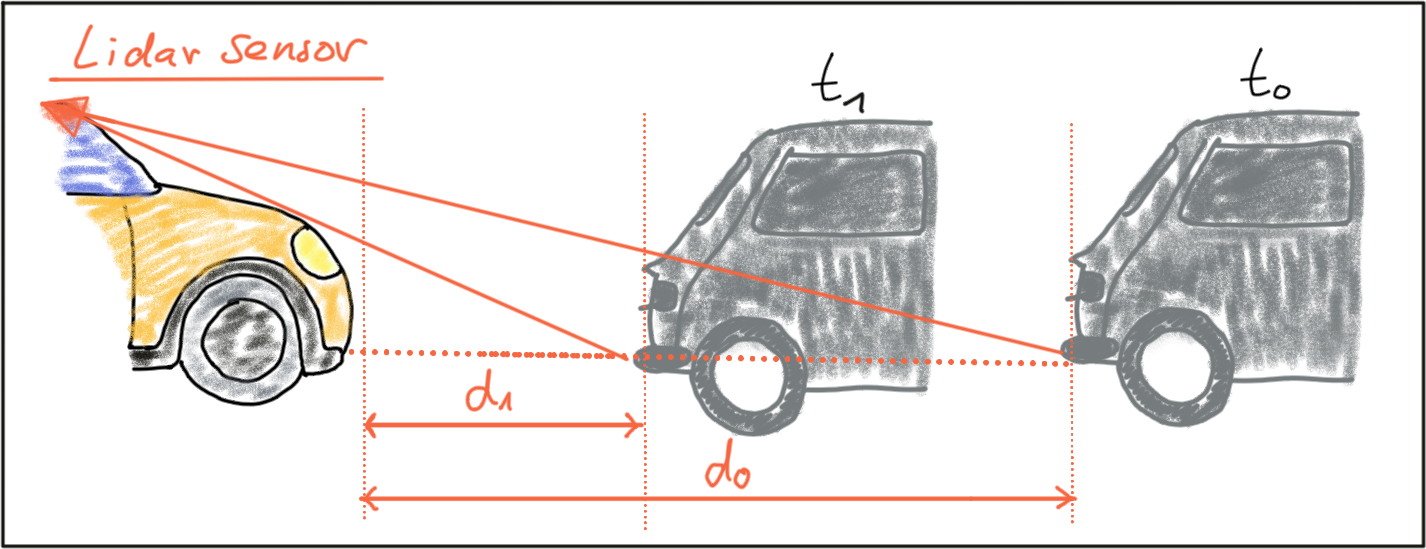

We can compute LiDAR based TTC from following equation above. So in order to compute the TTC, we need to find the distance to the closest LiDAR point in the path of driving, which is located on the tailgate of the preceding vehicle. Even though LiDAR is a reliable sensor, erroneous measurements may still occur. As seen in the figure below, a small number of points is located behind the tailgate, seemingly without connection to the vehicle.

In order to filter out these outliers, we implement K-D tree and euclidean cluster in this project. Basically we use all of the projected points to build the K-D tree, and clustering all of the points based on their euclidean distance. Points with large gap (euclidean distance more than certain threshold) will be clustered into separate clusters. And we will only choose the cluster with maximum size to calculate LiDAR based TTC. This is one of the are ways to avoid such errors by post-processing the point cloud, but there will be no guarantee that such problems will never occur in practice.
This part is implemented in "removeLidarOutlier" and "euclideanCluster" function.
-
Prepare the TTC computation based on camera measurements by associating keypoint correspondences to the bounding boxes which enclose them. All matches which satisfy this condition must be added to a vector in the respective bounding box.
In "clusterKptMatchesWithROI" function, we associate a given bounding box with the keypoints it contains. We iterate all of the key-point matches, and if the key-point can be found in the region of interest of our current bounding box, we will save current match to corresponding bounding box structure for calculating the camera based TTC.
Also, outlier matches have been removed based on the euclidean distance between them in relation to all the matches in the bounding box.
-
Compute the time-to-collision in second for all matched 3D objects using only keypoint correspondences from the matched bounding boxes between current and previous frame.
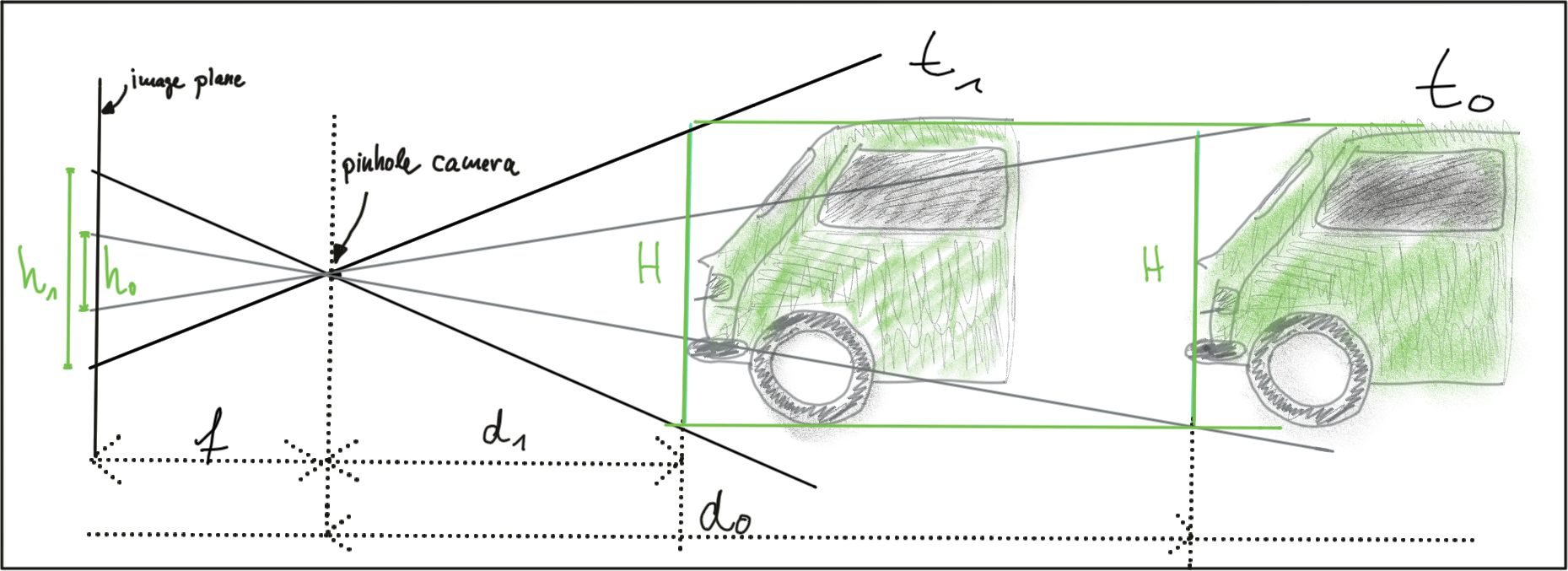

We can measure the time to collision by observing relative height change on the image sensor. However when observed closely however, it can be seen that the bounding boxes do not always reflect the true vehicle dimensions and the aspect ratio differs between images. Using bounding box height or width for TTC computation would thus lead to significant estimation errors.

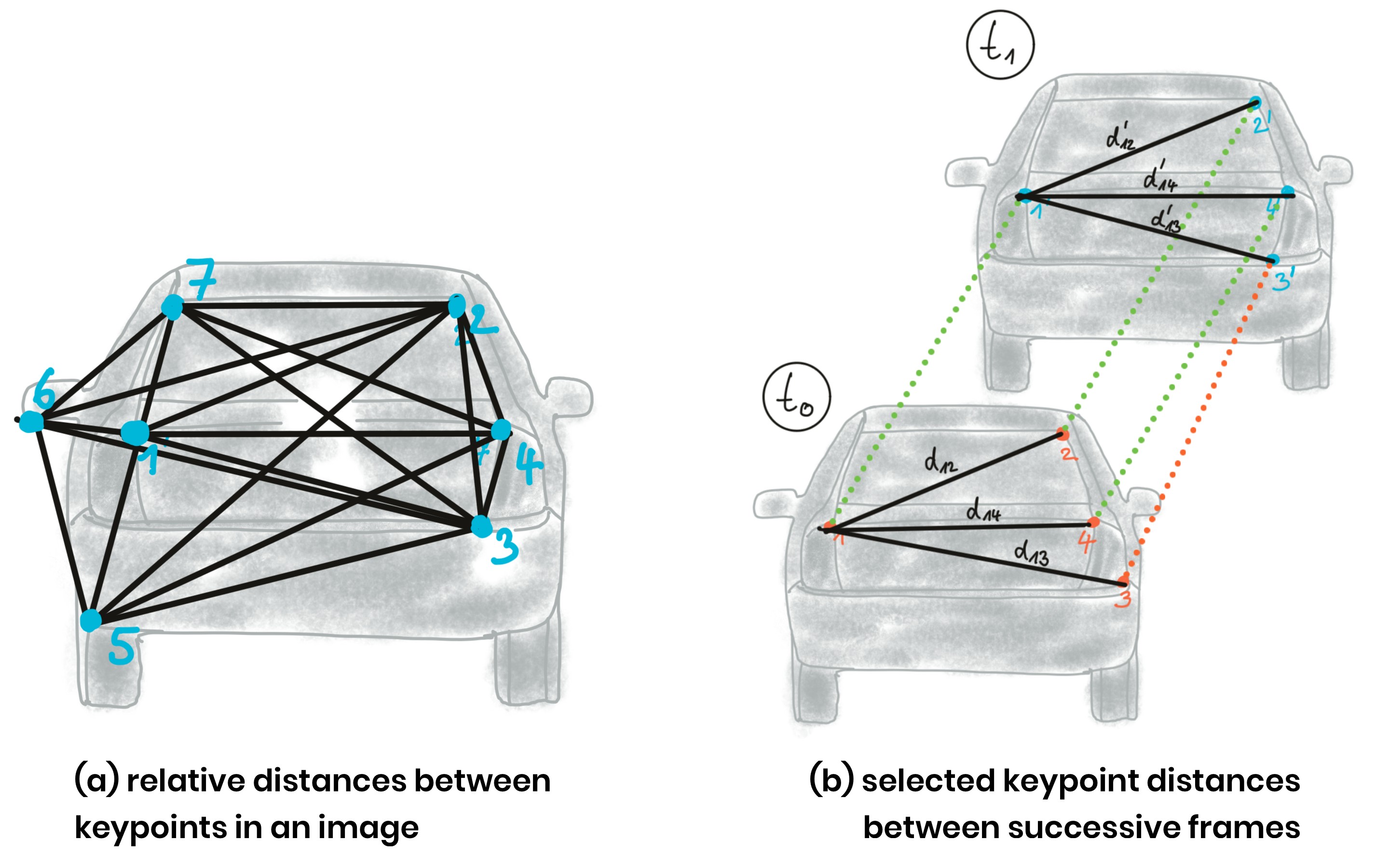
Instead of relying on the detection of the vehicle as a whole we now want to analyze its structure on a smaller scale. If were possible to locate uniquely identifiable keypoints that could be tracked from one frame to the next, we could use the distance between all keypoints on the vehicle relative to each other to compute a robust estimate of the height ratio in out TTC equation.
The ratio of all relative distances between each other can be used to compute a reliable TTC estimate by replacing the height ratio h1 / h0 with the mean or median of all distance ratios dk / dk'.
However, computing the mean distance ratio as in the function we just discussed would presumably lead to a faulty calculation of the TTC. A more robust way of computing the average of a dataset with outliers is to use the median instead.
This part is implemented in "computeTTCCamera" function.
-
Find examples where the TTC estimate of the Lidar sensor does not seem plausible. Describe your observations and provide a sound argumentation why you think this happened.
[Performance Evaluation 1 - LiDAR based TTC](#performance evaluation 1 - lidar)
-
Run several detector / descriptor combinations and look at the differences in TTC estimation. Find out which methods perform best and also include several examples where camera-based TTC estimation is way off. As with Lidar, describe your observations again and also look into potential reasons.
[Performance Evaluation 2 - Camera based TTC](#performance evaluation 2 - camera)









| TTC (in seconds) | LiDAR | Camera |
|---|---|---|
| Scenario 1 | 9.372 | 15.724 |
| Scenario 2 | 5.541 | 10.283 |
As we can see from the 2 scenarios above, there still have some noise or outliers even we implement euclidean clustering algorithm. These noise may come from:
- LiDAR and camera is not perfectly synchronized with each other
- LiDAR itself is not calibrated well
- The ground is not flatten, which causes some vibration during drive
And this kind of outliers will cause the estimated TTC less than actually TTC, because these outliers have smaller distance in longitudinal direction and we only consider the closest point when we calculate TTC. And the noise from previous frame will also affect TTC estimation in current frame, because we need to calculate the distance difference between two frames.
There are several ways that we can improve it:
- Instead of only considering 1 point, we can calculate TTC by using multiple point clouds. We can implement DBSCAN clustering algorithm, and take all non-core (edge) points from the largest cluster as input to calculate TTC
- Fuse with camera, we can remove lots of noise if camera can provide more accurate RoI of leading vehicle's rear bumper
- Add Kalman filter to tracking TTC by minimalizing covariance
Based on the and TTC data distribution and combine with our previous benchmark. Here is the top 3 detector / descriptor combinations:
-
FAST + BRIEF
-
FAST + ORB
-
FAST + BRISK
| Detectors\Descriptors | BRISK | BRIEF | ORB | FREAK | AKAZE | SIFT |
|---|---|---|---|---|---|---|
| SHITOMASI | 12.1209 | 11.2653 | 11.4615 | 11.466 | N/A | 11.2938 |
| HARRIS | 15.6701 | 62.0714 | 62.2064 | 17.682 | N/A | 17.3489 |
| FAST | 12.5592 | 12.5391 | 12.5228 | 12.8902 | N/A | 12.8837 |
| BRISK | 12.8156 | 12.447 | 13.3245 | 13.449 | N/A | 13.1422 |
| ORB | 13.3861 | 15.4395 | 15.0289 | 16.7056 | N/A | 5.01276 |
| AKAZE | 10.7705 | 11.043 | 10.9455 | 10.9082 | 10.9428 | 10.8828 |
| SIFT | 10.7146 | 10.732 | Out of Memory | 10.8749 | N/A | 11.0379 |
| Detectors\Descriptors | BRISK | BRIEF | ORB | FREAK | AKAZE | SIFT |
|---|---|---|---|---|---|---|
| SHITOMASI | 3.58203 | 2.44622 | 2.88165 | 2.87166 | N/A | 2.17353 |
| HARRIS | 5.38883 | 171.838 | 171.796 | 6.82063 | N/A | 6.04847 |
| FAST | 4.04397 | 3.73937 | 3.73738 | 3.97477 | N/A | 3.78585 |
| BRISK | 3.24327 | 2.8513 | 3.84271 | 4.82433 | N/A | 3.26171 |
| ORB | 3.72932 | 7.79276 | 5.28557 | 24.4952 | N/A | 29.2416 |
| AKAZE | 2.26705 | 2.50427 | 2.5179 | 2.40407 | 2.25899 | 2.22889 |
| SIFT | 2.23256 | 2.39566 | Out of Memory | 2.04645 | N/A | 2.55962 |
| Detectors\Descriptors | BRISK | BRIEF | ORB | FREAK | AKAZE | SIFT |
|---|---|---|---|---|---|---|
| SHITOMASI | 7.82528 | 8.20188 | 7.85682 | 7.98124 | N/A | 8.28579 |
| HARRIS | 8.6136 | 6.78412 | 7.20578 | 9.34511 | N/A | 6.78412 |
| FAST | 9.21822 | 8.4939 | 8.8245 | 9.44175 | N/A | 8.96297 |
| BRISK | 8.89592 | 9.46972 | 9.18967 | 9.35334 | N/A | 9.33849 |
| ORB | 9.22398 | 9.14645 | 9.2419 | -27.8105 | N/A | -97.2019 |
| AKAZE | 8.28244 | 7.98168 | 8.07032 | 8.46694 | 8.09656 | 7.90815 |
| SIFT | 8.06937 | 7.98048 | Out of Memory | 8.2683 | N/A | 8.46509 |
| Detectors\Descriptors | BRISK | BRIEF | ORB | FREAK | AKAZE | SIFT |
|---|---|---|---|---|---|---|
| SHITOMASI | 18.5628 | 16.7548 | 17.4185 | 17.4691 | N/A | 15.8739 |
| HARRIS | 25.4426 | 704.671 | 704.671 | 29.3158 | N/A | 27.0331 |
| FAST | 25.8856 | 21.4821 | 23.4077 | 25.9251 | N/A | 21.8186 |
| BRISK | 22.0756 | 18.2117 | 24.4255 | 29.6687 | N/A | 20.7219 |
| ORB | 23.14 | 38.492 | 26.8838 | 91.6054 | N/A | 22.6026 |
| AKAZE | 15.1287 | 16.1186 | 16.1617 | 15.6194 | 15.3061 | 15.0655 |
| SIFT | 15.647 | 15.5835 | Out of Memory | 15.2646 | N/A | 18.6955 |


| TTC (in seconds) | LiDAR | Camera |
|---|---|---|
| Scenario 1 | 5.8035 | 10.8997 |
| Scenario 2 | 9.3720 | 704.6714 |
As we can see from the 2 scenarios above, and compare with LiDAR based TTC estimation, there are several reasons that leads to inaccurate camera-based TTC estimation:
- Key-points mismatching, e.g. the key-point detected from turn signal lamp matches to the key-point on the roof in scenario 1.
- Sensitive scale change and significant contrast change. In scenario 2, some key-points from the rear part of the roof in previous frame associate with the key-points from front part of the roof in current frame. Part of the reason is due to contrast change from lighting conditions or occlusion. It makes the distance ratio between two frames very close to 1, so our host vehicle and preceding vehicle looks relatively static between 2 frames and our TTL turns out to be a pretty large value at the end.
There are several ways that we can improve it:
- Use more complex detector/descriptor combinations, e.g. SIFT, SIFT uses the Euclidean distance between two feature vectors as the similarity criteria of the two key points and uses the nearest neighbor algorithm to match each other. These kind of detector/descriptor is more accurate than any other descriptors and able to provide rotation and scale invariant.
- Fuse with LiDAR sensor, so that camera can provide more semantic information, such as key-points and matches between multiple frames, and LiDAR and provide more accurate direct distance measurement.
- Compare multiple frames instead of only considering 2 consecutive frames.
- Add Kalman filter to tracking TTC by minimalizing covariance