![]()

Xinqi Lin1,*, Jingwen He2,3,*, Ziyan Chen1, Zhaoyang Lyu2, Bo Dai2, Fanghua Yu1, Wanli Ouyang2, Yu Qiao2, Chao Dong1,2
1Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
2Shanghai AI Laboratory
3The Chinese University of Hong Kong


⭐If DiffBIR is helpful for you, please help star this repo. Thanks!🤗
- 2024.04.08: ✅ Release everything about our updated manuscript, including (1) a new model trained on subset of laion2b-en and (2) a more readable code base, etc. DiffBIR is now a general restoration pipeline that could handle different blind image restoration tasks with a unified generation module.
- 2023.09.19: ✅ Add support for Apple Silicon! Check installation_xOS.md to work with CPU/CUDA/MPS device!
- 2023.09.14: ✅ Integrate a patch-based sampling strategy (mixture-of-diffusers). Try it! Here is an example with a resolution of 2396 x 1596. GPU memory usage will continue to be optimized in the future and we are looking forward to your pull requests!
- 2023.09.14: ✅ Add support for background upsampler (DiffBIR/RealESRGAN) in face enhancement! 🚀 Try it!
- 2023.09.13: 🚀 Provide online demo (DiffBIR-official) in OpenXLab, which integrates both general model and face model. Please have a try! camenduru also implements an online demo, thanks for his work.:hugs:
- 2023.09.12: ✅ Upload inference code of latent image guidance and release real47 testset.
- 2023.09.08: ✅ Add support for restoring unaligned faces.
- 2023.09.06: 🚀 Update colab demo. Thanks to camenduru!:hugs:
- 2023.08.30: This repo is released.
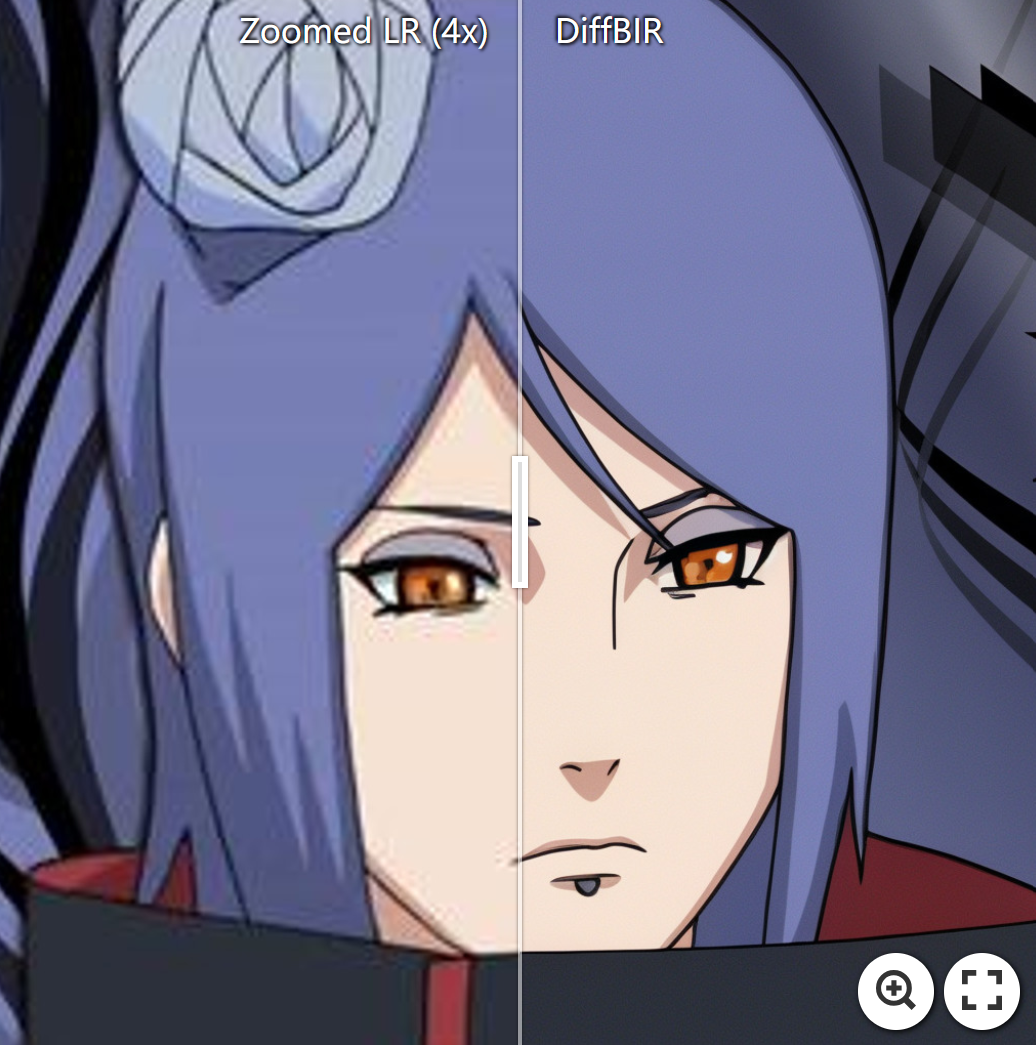




⭐ Face and the background enhanced by DiffBIR.



I often think of Bag End. I miss my books and my arm chair, and my garden. See, that's where I belong. That's home. --- Bilbo Baggins

- Release code and pretrained models 💻.
- Update links to paper and project page 🔗.
- Release real47 testset 💽.
- Provide webui.
- Reduce the vram usage of DiffBIR 🔥🔥🔥.
- Provide HuggingFace demo 📓.
- Add a patch-based sampling schedule 🔍.
- Upload inference code of latent image guidance 📄.
- Improve the performance 🦸.
- Support MPS acceleration for MacOS users.
- DiffBIR-turbo 🔥🔥🔥.
- Speed up inference, such as using fp16/bf16, torch.compile 🔥🔥🔥.
# clone this repo
git clone https://github.com/XPixelGroup/DiffBIR.git
cd DiffBIR
# create environment
conda create -n diffbir python=3.10
conda activate diffbir
pip install -r requirements.txtOur new code is based on pytorch 2.2.2 for the built-in support of memory-efficient attention. If you are working on a GPU that is not compatible with the latest pytorch, just downgrade pytorch to 1.13.1+cu116 and install xformers 0.0.16 as an alternative.
Here we list pretrained weight of stage 2 model (IRControlNet) and our trained SwinIR, which was used for degradation removal during the training of stage 2 model.
| Model Name | Description | HuggingFace | BaiduNetdisk | OpenXLab |
|---|---|---|---|---|
| v2.pth | IRControlNet trained on filtered laion2b-en | download | download (pwd: xiu3) |
download |
| v1_general.pth | IRControlNet trained on ImageNet-1k | download | download (pwd: 79n9) |
download |
| v1_face.pth | IRControlNet trained on FFHQ | download | download (pwd: n7dx) |
download |
| codeformer_swinir.ckpt | SwinIR trained on ImageNet-1k | download | download (pwd: vfif) |
download |
During inference, we use off-the-shelf models from other papers as the stage 1 model: BSRNet for BSR, SwinIR-Face used in DifFace for BFR, and SCUNet-PSNR for BID, while the trained IRControlNet remains unchanged for all tasks. Please check code for more details. Thanks for their work!
We provide some examples for inference, check inference.py for more arguments. Pretrained weights will be automatically downloaded.
python -u inference.py \
--version v2 \
--task sr \
--upscale 4 \
--cfg_scale 4.0 \
--input inputs/demo/bsr \
--output results/demo_bsr \
--device cuda# for aligned face inputs
python -u inference.py \
--version v2 \
--task fr \
--upscale 1 \
--cfg_scale 4.0 \
--input inputs/demo/bfr/aligned \
--output results/demo_bfr_aligned \
--device cuda# for unaligned face inputs
python -u inference.py \
--version v2 \
--task fr_bg \
--upscale 2 \
--cfg_scale 4.0 \
--input inputs/demo/bfr/whole_img \
--output results/demo_bfr_unaligned \
--device cudapython -u inference.py \
--version v2
--task dn \
--upscale 1 \
--cfg_scale 4.0 \
--input inputs/demo/bid \
--output results/demo_bid \
--device cudaAdd the following arguments to enable patch-based sampling:
[command...] --tiled --tile_size 512 --tile_stride 256Patch-based sampling supports super-resolution with a large scale factor. Our patch-based sampling is built upon mixture-of-diffusers. Thanks for their work!
Restoration guidance is used to achieve a trade-off bwtween quality and fidelity. We default to closing it since we prefer quality rather than fidelity. Here is an example:
python -u inference.py \
--version v2 \
--task sr \
--upscale 4 \
--cfg_scale 4.0 \
--input inputs/demo/bsr \
--guidance --g_loss w_mse --g_scale 0.5 --g_space rgb \
--output results/demo_bsr_wg \
--device cudaYou will see that the results become more smooth.
Add the following argument to offer better start point for reverse sampling:
[command...] --better_startThis option prevents our model from generating noise in image background.
First, we train a SwinIR, which will be used for degradation removal during the training of stage 2.
-
Generate file list of training set and validation set, a file list looks like:
/path/to/image_1 /path/to/image_2 /path/to/image_3 ...
You can write a simple python script or directly use shell command to produce file lists. Here is an example:
# collect all iamge files in img_dir find [img_dir] -type f > files.list # shuffle collected files shuf files.list > files_shuf.list # pick train_size files in the front as training set head -n [train_size] files_shuf.list > files_shuf_train.list # pick remaining files as validation set tail -n +[train_size + 1] files_shuf.list > files_shuf_val.list
-
Fill in the training configuration file with appropriate values.
-
Start training!
accelerate launch train_stage1.py --config configs/train/train_stage1.yaml
-
Download pretrained Stable Diffusion v2.1 to provide generative capabilities. 💡: If you have ran the inference script, the SD v2.1 checkpoint can be found in weights.
wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt --no-check-certificate
-
Generate file list as mentioned above. Currently, the training script of stage 2 doesn't support validation set, so you only need to create training file list.
-
Fill in the training configuration file with appropriate values.
-
Start training!
accelerate launch train_stage2.py --config configs/train/train_stage2.yaml
Please cite us if our work is useful for your research.
@misc{lin2024diffbir,
title={DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior},
author={Xinqi Lin and Jingwen He and Ziyan Chen and Zhaoyang Lyu and Bo Dai and Fanghua Yu and Wanli Ouyang and Yu Qiao and Chao Dong},
year={2024},
eprint={2308.15070},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
This project is released under the Apache 2.0 license.
This project is based on ControlNet and BasicSR. Thanks for their awesome work.
If you have any questions, please feel free to contact with me at linxinqi23@mails.ucas.ac.cn.