OSSChat | Documentation | Contact | LICENSE
Index
ChatGPT has constraints due to its limited knowledge base, sometimes resulting in hallucinating answers when asked about unfamiliar topics. We are introducing the new AI stack, ChatGPT+Vector database+prompt-as-code, or the CVP Stack, to overcome this constraint.
We have built OSSChat as a working demonstration of the CVP stack. Now we are presenting the technology behind OSSChat in this repository with a code name of Akcio.

|

|
With this project, you are able to build a knowledge-enhanced ChatBot using LLM service like ChatGPT. By the end, you will learn how to start a backend service using FastAPI, which provides standby APIs to support further applications. Alternatively, we show how to use Gradio to build an online demo.

Akcio allows you to create a ChatGPT-like system with added intelligence obtained through semantic search of customized knowledge base. Instead of sending the user query directly to LLM service, our system firstly retrieves relevant information from stores by semantic search or keyword match. Then it feeds both user needs and helpful information into LLM. This allows LLM to better tailor its response to the user's needs and provide more accurate and helpful information.
You can find more details and instructions at our documentation.
Akcio offers two AI platforms to choose from: Towhee or LangChain. It also supports different integrations of LLM service and databases:
| Towhee | LangChain | ||
|---|---|---|---|
| LLM | OpenAI | ✓ | ✓ |
| Llama-2 | ✓ | ||
| Dolly | ✓ | ✓ | |
| Ernie | ✓ | ✓ | |
| MiniMax | ✓ | ✓ | |
| DashScope | ✓ | ||
| ChatGLM | ✓ | ||
| SkyChat | ✓ | ||
| Embedding | OpenAI | ✓ | ✓ |
| HuggingFace | ✓ | ✓ | |
| Vector Store | Zilliz Cloud | ✓ | ✓ |
| Milvus | ✓ | ✓ | |
| Scalar Store (Optional) | Elastic | ✓ | ✓ |
| Memory Store | Postgresql | ✓ | ✓ |
| MySQL and MariaDB | ✓ | ||
| SQLite | ✓ | ✓ | |
| Oracle | ✓ | ||
| Microsoft SQL Server | ✓ | ||
| Rerank | MS MARCO Cross-Encoders | ✓ |
The option using Towhee simplifies the process of building a system by providing pre-defined pipelines. These built-in pipelines require less coding and make system building much easier. If you require customization, you can either simply modify configuration or create your own pipeline with rich options of Towhee Operators.
-
- Insert: The insert pipeline builds a knowledge base by saving documents and corresponding data in database(s).
- Search: The search pipeline enables the question-answering capability powered by information retrieval (semantic search and optional keyword match) and LLM service.
- Prompt: a prompt operator prepares messages for LLM by assembling system message, chat history, and the user's query processed by template.
-
Memory: The memory storage stores chat history to support context in conversation. (available: most SQL)
The option using LangChain employs the use of Agent in order to enable LLM to utilize specific tools, resulting in a greater demand for LLM's ability to comprehend tasks and make informed decisions.
- Agent
- ChatAgent: agent ensembles all modules together to build up qa system.
- Other agents (todo)
- LLM
- ChatLLM: large language model or service to generate answers.
- Embedding
- TextEncoder: encoder converts each text input to a vector.
- Other encoders (todo)
- Store
- VectorStore: vector database stores document chunks in embeddings, and performs document retrieval via semantic search.
- ScalarStore: optional, database stores metadata for each document chunk, which supports additional information retrieval. (available: Elastic)
- MemoryStore: memory storage stores chat history to support context in conversation.
- DataLoader
- DataParser: tool loads data from given source and then splits documents into processed doc chunks.
-
Downloads
$ git clone https://github.com/zilliztech/akcio.git $ cd akcio -
Install dependencies
$ pip install -r requirements.txt
-
Configure modules
You can configure all arguments by modifying config.py to set up your system with default modules.
-
LLM
By default, the system will use OpenAI service as the LLM option. To set your OpenAI API key without modifying the configuration file, you can pass it as environment variable.
$ export OPENAI_API_KEY=your_keys_hereCheck how to SWITCH LLM.
If you want to use another supported LLM service, you can change the LLM option and set up for it. Besides directly modifying the configuration file, you can also set up via environment variables.-
For example, to use Llama-2 at local which does not require any account, you just need to change the LLM option:
$ export LLM_OPTION=llama_2 -
For example, to use Ernie instead of OpenAI, you need to change the option and set up ERNIE Bot SDK token :
$ export LLM_OPTION=ernie $ export EB_API_TYPE=your_api_type $ export EB_ACCESS_TOKEN=your_ernie_access_token
-
-
Embedding
By default, the embedding module uses methods from Sentence Transformers to convert text inputs to vectors. Here are some information about the default embedding method:
- model: BAAI/bge-base-en
- dim: 768
- normalization: True
-
Store
Before getting started, all database services used for store must be running and be configured with write and create access.
- Vector Store: You need to prepare the service of vector database in advance. For example, you can refer to Milvus Documents or Zilliz Cloud to learn about how to start a Milvus service.
- Scalar Store (Optional): This is optional, only work when
USE_SCALARis true in configuration. If this is enabled (i.e. USE_SCALAR=True), the default scalar store will use Elastic. In this case, you need to prepare the Elasticsearch service in advance. - Memory Store: By default, both LangChain and Towhee mode allow interaction with any database supported by SQLAlchemy 2.0.
The system will use default store configs. To set up your special connections for each database, you can also export environment variables instead of modifying the configuration file.
For the Vector Store, set ZILLIZ_URI:
$ export ZILLIZ_URI=your_zilliz_cloud_endpoint $ export ZILLIZ_TOKEN=your_zilliz_cloud_api_key # skip this if using Milvus instance
For the Memory Store, set SQL_URI:
$ export SQL_URI={database_type}://{user}:{password}@{host}/{database_name}By default, scalar store (elastic) is disabled. Click to check how to enable Elastic.
The following commands help to connect your Elastic cloud.
$ export USE_SCALAR=True $ export ES_CLOUD_ID=your_elastic_cloud_id $ export ES_USER=your_elastic_username $ export ES_PASSWORD=your_elastic_password
To use host & port instead of cloud id, you can manually modify the
VECTORDB_CONFIGin config.py.
-
-
Start service
The main script will run a FastAPI service with default address
localhost:8900.- Option 1: using Towhee
$ python main.py --towhee
- Option 2: using LangChain
$ python main.py --langchain
- Option 1: using Towhee
-
Access via browser
You can open url http://localhost:8900/docs in browser to access the web service.
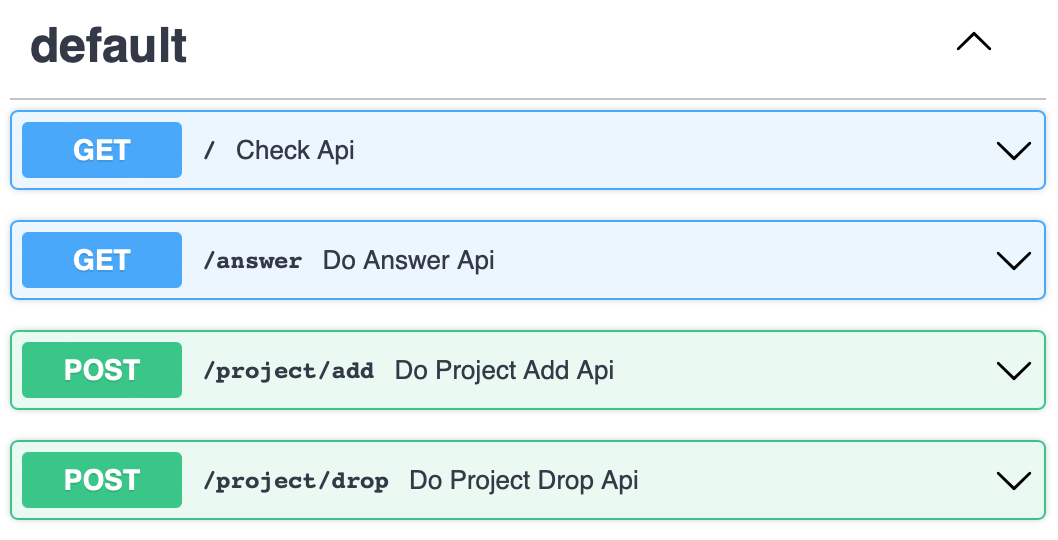
/: Check service status/answer: Generate answer for the given question, with assigned session_id and project/project/add: Add data to project (will create the project if not exist)/project/drop: Drop project including delete data in both vector and memory storages.Check Online Operations to learn more about these APIs.

The insert function in operations loads project data from url(s) or file(s).
There are 2 options to load project data:
We recommend this method, which loads data in separate steps. There is also advanced options to load document, for example, generating and inserting potential questions for each doc chunk. Refer to offline_tools for instructions.
When the FastAPI service is up, you can use the POST request http://localhost:8900/project/add to load data.
Parameters:
{
"project": "project_name",
"data_src": "path_to_doc",
"source_type": "file"
}or
{
"project": "project_name",
"data_src": "doc_url",
"source_type": "url"
}This method is only recommended to load a small amount of data, but not for a large amount of data.
Akcio is published under the Server Side Public License (SSPL) v1.