FPGA-based Acceleration of Video Depth Estimation by HW/SW Co-design
Copyright 2022, Nobuho Hashimoto and Shinya Takamaeda-Yamazaki
If you use FADEC in your research, please cite our paper.
@INPROCEEDINGS{9974565,
author = {Hashimoto, Nobuho and Takamaeda-Yamazaki, Shinya},
booktitle = {2022 International Conference on Field-Programmable Technology (ICFPT)},
title = {{FADEC: FPGA-based Acceleration of Video Depth Estimation by HW/SW Co-design}},
year = {2022},
volume = {},
number = {},
pages = {1-9},
doi = {10.1109/ICFPT56656.2022.9974565}
}
For further information on our paper, you can view the following materials.
This is a novel FPGA-based accelerator for a depth estimation method "DeepVideoMVS", which alternates between traditional image/video processing algorithms and DNNs. We employ HW/SW co-design to appropriately utilize heterogeneous components in modern SoC FPGAs, such as programmable logic (PL) and CPU, according to the inherent characteristics of the method. The hardware and software implementations are executed in parallel on the PL and CPU to hide their execution latencies. This accelerator was developed on a Xilinx ZCU104 board by using NNgen, an open-source high-level synthesis (HLS) tool. Experiments showed that this accelerator operates 60.2 times faster than the software-only implementation on the same FPGA board with minimal accuracy degradation.
- Prepare pre-trained weights and datasets
- Adjust datasets to our implementation
- Quantize weights and activation
- Export network input and output
- Export HDL using NNgen
- Generate bitstream using Vivado
- Execute FADEC on ZCU104
- Evaluate results
Note: If you just want to execute and evaluate FADEC, move to 7. Execute FADEC on ZCU104.
- Python 3.8.12
- numpy==1.20.3
- opencv-contrib-python==4.5.4.60
- path==15.0.0
- torch==1.5.1+cu101
- torchvision==0.6.1+cu101
Warning: As we customized NNgen, we don't recommend you install NNgen by pip (Installation guideline is in 5. Export HDL using NNgen.).
- Python 3.8.2
- nngen==1.3.3
- numpy==1.22.3
- onnx==1.11.0
- pyverilog==1.3.0
- torch==1.11.0
- veriloggen==2.1.0
Note: The environment is changed from "1st to 4th" because we used different machines.
- Vivado v2021.2
- ZCU104 board with Zynq UltraScale+ MPSoC XCZU7EV-2FFVC1156 from Xilinx
- PYNQ Linux 2.6, based on Ubuntu 18.04 (GNU/Linux 5.4.0-xilinx-v2020.1 aarch64)
- Python 3.6.5
- Cython==0.29
- numpy==1.16.0
- torch==1.10.2
- g++ (Ubuntu/Linaro 7.3.0-16ubuntu3) 7.3.0 (for the 8th)
- OpenCV v3.4.3
- Eigen v3.3.4
Files in ./dev/params
- params_cpp.zip: Params used for cpp evaluation.
- params_cpp_with_ptq.zip: Quantized params used for cpp_with_ptq evaluation.
- quantized_params.zip: Quantized params, input data, and output data for HDL export.
- flattened_params.zip: Flattened params for FADEC evaluation.
Note: You can generate these parameters by yourself by following the instructions.
-
Download the pre-trained weights from ardaduz/deep-video-mvs/dvmvs/fusionnet/weights.
-
Place it under
./dev/params.- The directory name should be changed from
weightstoorg_weights. - The path should be
./dev/params/org_weights.
- The directory name should be changed from
-
Download the
hololensdataset from ardaduz/deep-video-mvs/sample-data/hololens-dataset. -
Place it under
./dev/dataset.- The path should be
./dev/dataset/hololens-dataset.
- The path should be
-
Download the
7scenesdataset from RGB-D Dataset 7-Scenes. -
Unzip the files.
- Note: We just use the following eight scenes:
redkitchen/seq-01,redkitchen/seq-07,chess/seq-01,chess/seq-02,fire/seq-01,fire/seq-02,office/seq-01,office/seq-03.
- Note: We just use the following eight scenes:
-
Set the downloaded 7scenes path to the
input_foldervariable in./dev/dataset/7scenes_export.py. -
Execute the script by the following command.
$ cd dev/dataset $ python3 7scenes_export.py- Outputs will be stored in
./dev/dataset/7scenes.
- Outputs will be stored in
-
Input data are
./dev/dataset/hololens-datasetand./dev/dataset/7scenes. -
Execute
./dev/dataset_converter/hololens/convert_hololens.pyand./dev/dataset_converter/7scenes/convert_7scenes.pyby the following commands.$ cd dev/dataset_converter/hololens $ python3 convert_hololens.py $ cd ../7scenes $ python3 convert_7scenes.py
- Outputs will be stored in
hololens/images_hololens,7scenes/images_7scenes, and7scenes/data_7scenes.
- Outputs will be stored in
-
Execute
./dev/quantizer/convert_models.pyby the following commands.$ cd dev/quantizer $ python3 convert_models.py- Outputs will be stored in
./dev/params/params_cpp. - Data stored in
./dev/params/org_weights_binis temporary output, so never used again.
- Outputs will be stored in
-
Execute
./dev/quantizer/weight_quantization.pyby the following commands.$ cd dev/quantizer $ python3 weight_quantization.py- Outputs will be stored in
./dev/params/params_cpp_with_ptqand./dev/params/quantized_params.
- Outputs will be stored in
-
Execute
./dev/quantizer/activation_extraction.pyby the following commands.$ cd dev/quantizer $ python3 activation_extraction.py- Data stored in
./dev/params/tmpis temporary output, so never used again.
- Data stored in
-
Execute
./dev/quantizer/activation_quantization.pyby the following commands.$ cd dev/quantizer $ python3 activation_quantization.py- Outputs will be added to
./dev/params/params_cpp_with_ptq.
- Outputs will be added to
-
Execute
./dev/quantizer/export_inout.pyby the following commands.$ cd dev/quantizer $ python3 export_inout.py- Outputs will be added to
./dev/params/quantized_params.
- Outputs will be added to
-
Install NNgen by the following commands.
$ git clone https://github.com/NNgen/nngen.git $ cd nngen $ git checkout v1.3.3 $ cp -r ../dev/export_hdl/nngen_patch/* nngen/ $ python3 setup.py install
-
Execute
./dev/export_hdl/dvmvs.pyby the following commands.$ cd dev/export_hdl $ python3 dvmvs.py- Outputs will be stored in
./dev/export_hdl/dvmvs_v1_0and./dev/params/flattened_params.
- Outputs will be stored in
-
Execute
./dev/vivado/generate_bitstream.shby the following commands.$ cd dev/vivado $ ./generate_bitstream.sh- Outputs will be stored in
./dev/vivado/dvmvs. - Bitstream files will be stored in
./dev/vivado/design_1. - Note: It will take some hours to finish.
- Outputs will be stored in
-
The design image is shown in the figure below.
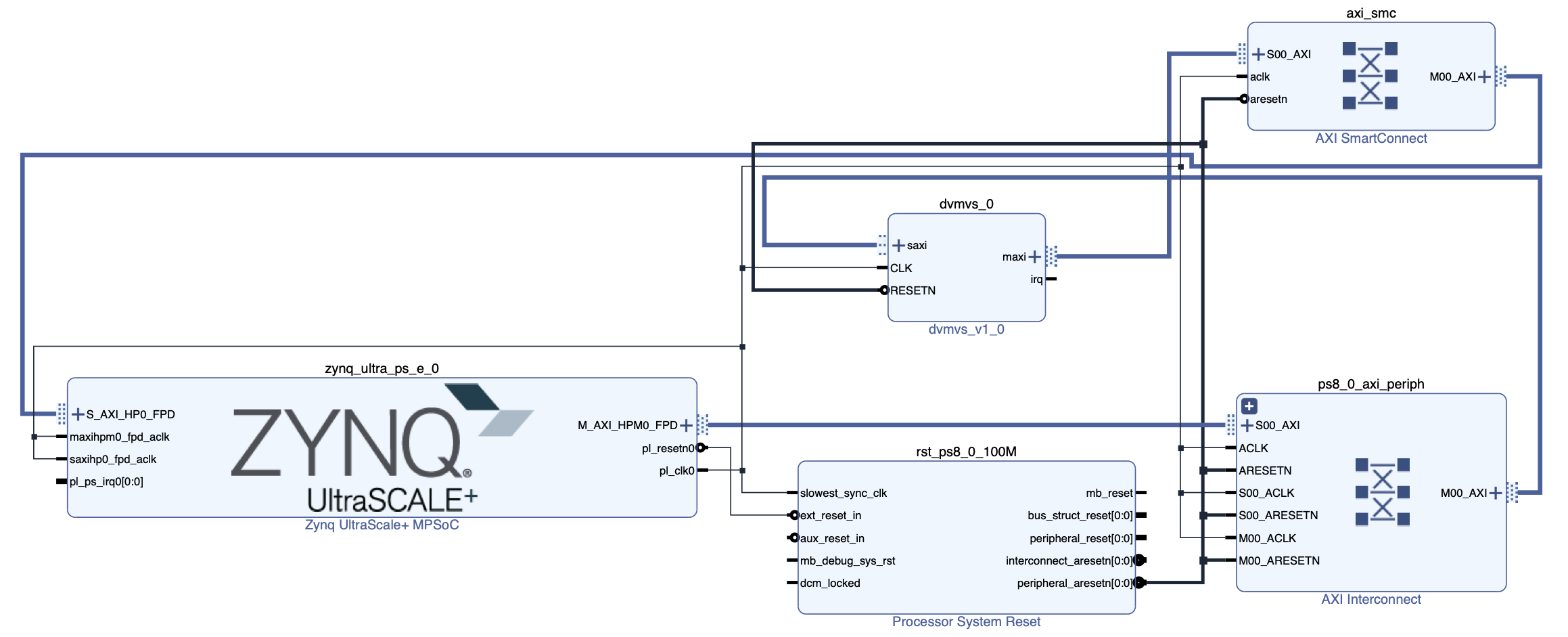

-
Prepare datasets by following the 1st and 2nd procedures if necessary.
-
Download and place
flattened_paramsunder./eval/fadecfrom flattened_params.zip if necessary. -
Place
./eval/fadecon ZCU104. -
Place
design_1.bitanddesign_1.hwhin the directory on ZCU104.-
./dev/vivado/move_bitstream.shis helpful to move these files.$ cd dev/vivado $ ./move_bitstream.sh /path/to/dev/vivado pynq:/path/to/fadec # You can also specify a remote directory for the former one.
-
You can also download these files from design_1.zip
-
-
Compile
./eval/fadec/fusion.pyxon ZCU104 by the following commands.$ cd /path/to/fadec $ make -
Execute
./eval/fadec/7scenes_evaluation.ipynbon ZCU104.-
Outputs will be stored in
depthsandtime_fadec.txt. -
If the following error happens in the 7th cell, reboot ZCU104 and retry.
Output exceeds the size limit. Open the full output data in a text editor --------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-7-6778394090c9> in <module>() 1 memory_size = 1024 * 1024 * 192 ----> 2 buf = allocate(shape=(memory_size,), dtype=np.uint8) 3 buf[param_offset:param_offset + params.size] = params.view(np.int8) /usr/local/lib/python3.6/dist-packages/pynq/buffer.py in allocate(shape, dtype, target, **kwargs) 170 if target is None: 171 target = Device.active_device --> 172 return target.allocate(shape, dtype, **kwargs) /usr/local/lib/python3.6/dist-packages/pynq/pl_server/device.py in allocate(self, shape, dtype, **kwargs) 292 293 """ --> 294 return self.default_memory.allocate(shape, dtype, **kwargs) 295 296 def reset(self, parser=None, timestamp=None, bitfile_name=None): /usr/local/lib/python3.6/dist-packages/pynq/xlnk.py in allocate(self, *args, **kwargs) 255 256 """ --> 257 return self.cma_array(*args, **kwargs) 258 259 def cma_array(self, shape, dtype=np.uint32, cacheable=0, ... --> 226 raise RuntimeError("Failed to allocate Memory!") 227 self.bufmap[buf] = length 228 return self.ffi.cast(data_type + "*", buf) RuntimeError: Failed to allocate Memory!
-
- Prepare datasets by following the 1st and 2nd procedures if necessary.
- Download and place
params_cppunder./eval/cppfrom params_cpp.zip if necessary. - Download and place
params_cpp_with_ptqunder./eval/cpp_with_ptqfrom params_cpp_with_ptq.zip if necessary. - Place
./eval/cppand./eval/cpp_with_ptqon ZCU104.- Be careful that
images_7scenesdirectory in those directories may be too large to place on ZCU104. - If you cannot place all the data together, place some of the directories in
images_7sceneson ZCU104.
- Be careful that
-
Execute C++ implementations by the following commands on ZCU104.
$ cd /path/to/cpp $ make $ ./a.out > time_cpp.txt $ cd /path/to/cpp_with_ptq $ make $ ./a.out > time_cpp_with_ptq.txt
- Outputs will be stored in
results_7scenesand (time_cpp.txtortime_cpp_with_ptq.txt).
- Outputs will be stored in
-
Execute
./eval/calculate_time.pyby the following commands.$ cd /path/to/eval $ python3 calculate_time.py CPU-only: median 16.833 std: 0.048 CPU-only (w/ PTQ): median 13.185 std: 0.040 PL + CPU (ours): median 0.278 std: 0.118-
The execution time per frame is shown in the table below.
Platform median [s] std [s] CPU-only 16.744 0.049 CPU-only (w/ PTQ) 13.248 0.035 PL + CPU (ours) 0.278 0.118 -
Note: The results in this project have some measurement errors compared with those in the paper.
-
-
Execute
./eval/fadec/overhead_evaluation.ipynbon ZCU104 to measure the overhead time.- The overhead is 4.7 ms.
- The final cell shows the overhead time.
- Note: The results in this project have some measurement errors compared with those in the paper.
-
See
Open Implemented Design > Timing > Clock Summaryin Vivado to check the clock frequency.
- The frequency is 187.512 MHz.

-
Run
Open Implemented Design > Report Utilizationin Vivado.
-
The hardware resource utilization is shown in the table below.
Name #Utilization Available Utilization [%] Slice 28256 28800 98.1 LUT 176377 230400 76.6 FF 143072 460800 31.0 DSP 128 1728 7.41 BRAM 309 312 99.0
-

-
Execute
./eval/calculate_errors.pyby the following commands.$ cd /path/to/eval $ python3 calculate_errors.py-
The MSE values for each scene and implementation are printed.
Dataset Nemes: ['chess-seq-01', 'chess-seq-02', 'fire-seq-01', 'fire-seq-02', 'office-seq-01', 'office-seq-03', 'redkitchen-seq-01', 'redkitchen-seq-07'] MSE: C++: [0.95 0.78 0.51 0.38 0.57 0.35 0.77 0.74] C++ (w/ PTQ): [1.04 0.89 0.57 0.42 0.73 0.48 0.86 0.85] Ours: [1.01 0.85 0.54 0.4 0.67 0.42 0.78 0.79] -
The graph will be saved in
./eval/errors.png.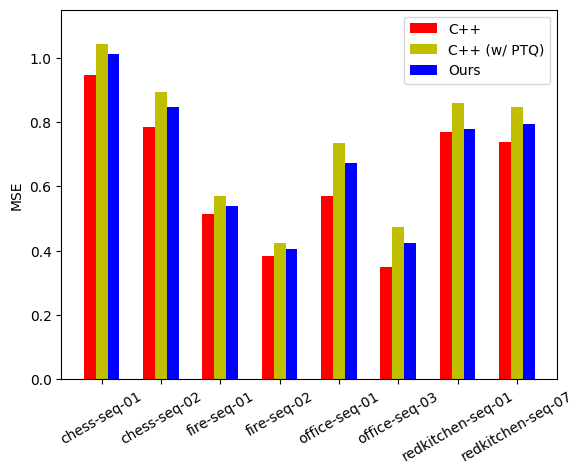
-
-
Use
./eval/visualize_image.ipynbfor qualitative evaluation.


@inproceedings{Duzceker_2021_CVPR,
author = {Duzceker, Arda and Galliani, Silvano and Vogel, Christoph and
Speciale, Pablo and Dusmanu, Mihai and Pollefeys, Marc},
title = {DeepVideoMVS: Multi-View Stereo on Video With Recurrent Spatio-Temporal Fusion},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {15324-15333}
}