A collection of resources on multimodal learning research.
🐌 Markdown Format:
🌱: Novel idea📌: The first...- 🚀: State-of-the-Art
- 👑: Novel dataset/model
- 📚:Downstream Tasks
-
- (TPAMI 2023) Multimodal Image Synthesis and Editing: A Survey and Taxonomy, Fangneng Zhan et al. [v1](2021.12.27) ... [v5](2023.08.05)
- (TPAMI 2023) [💬Transformer] Multimodal Learning with Transformers: A Survey, Peng Xu et al. [v1](2022.06.13) [v2](2023.05.11)
- (Multimedia Tools and Applications) A comprehensive survey on generative adversarial networks used for synthesizing multimedia content, Lalit Kumar & Dushyant Kumar Singh [v1](2023.03.30)
- ⭐⭐(arXiv preprint 2023) Multimodal Deep Learning, Cem Akkus et al. [v1](2023.01.12)
- ⭐(arXiv preprint 2022) [💬Knowledge Enhanced] A survey on knowledge-enhanced multimodal learning, Maria Lymperaiou et al. [v1](2022.11.19)
- ⭐⭐(arXiv preprint 2022) Vision-Language Pre-training: Basics, Recent Advances, and Future Trends, Zhe Gan et al. [v1](2022.10.17)
- ⭐(arXiv preprint 2022) Vision+X: A Survey on Multimodal Learning in the Light of Data, Ye Zhu et al. [v1](2022.10.05)
- (arXiv preprint 2022) Foundations and Recent Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions, Paul Pu Liang et al. [v1](2022.09.07)
- (arXiv preprint 2022) [💬Cardiac Image Computing] Multi-Modality Cardiac Image Computing: A Survey, Lei Li et al. [v1](2022.08.26)
- (arXiv preprint 2022) [💬Vision and language Pre-training (VLP)] Vision-and-Language Pretraining, Thong Nguyen et al. [v1](2022.07.05)
- (arXiv preprint 2022) [💬Video Saliency Detection] A Comprehensive Survey on Video Saliency Detection with Auditory Information: the Audio-visual Consistency Perceptual is the Key!, Chenglizhao Chen et al. [v1](2022.06.20)
- (arXiv preprint 2022) [💬Vision and language Pre-training (VLP)] Vision-and-Language Pretrained Models: A Survey, Siqu Long et al. [v1](2022.04.15)...[v5](2022.05.03)
- (arXiv preprint 2022) [💬Vision and language Pre-training (VLP)] VLP: A Survey on Vision-Language Pre-training, Feilong Chen et al. [v1](2022.02.18) [v2](2022.02.21)
- (arXiv preprint 2022) [💬Vision and language Pre-training (VLP)] A Survey of Vision-Language Pre-Trained Models, Yifan Du et al. [v1](2022.02.18)
- (arXiv preprint 2022) [💬Multi-Modal Knowledge Graph] Multi-Modal Knowledge Graph Construction and Application: A Survey, Xiangru Zhu et al. [v1](2022.02.11)
- (arXiv preprint 2022) [💬Auto Driving] Multi-modal Sensor Fusion for Auto Driving Perception: A Survey, Keli Huang et al. [v1](2022.02.06) [v2](2022.02.27)
- (arXiv preprint 2021) A Survey on Multi-modal Summarization, Anubhav Jangra et al. [v1](2021.09.11)
- (Information Fusion 2021) [💬Vision and language] Multimodal research in vision and language: A review of current and emerging trends, ShagunUppal et al. [v1](2021.08.01)
-
👑 Dataset
- (arXiv preprint 2023) Sticker820K: Empowering Interactive Retrieval with Stickers, Sijie Zhao et al. [Paper] [Github]
- (arXiv preprint 2023) Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration, Chenyang Lyu et al. [Paper] [Github]
- (arXiv preprint 2022) Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework, Jiaxi Gu et al. [Paper] [Download]
- The Noah-Wukong dataset is a large-scale multi-modality Chinese dataset.
- The dataset contains 100 Million <image, text> pairs
- Images in the datasets are filtered according to the size ( > 200px for both dimensions ) and aspect ratio ( 1/3 ~ 3 )
- Text in the datasets are filtered according to its language, length and frequency. Privacy and sensitive words are also taken into consideration.
- (arXiv preprint 2022) WuDaoMM: A large-scale Multi-Modal Dataset for Pre-training models, Sha Yuan et al. [Paper] [Download]
-
💬 Vision and language Pre-training (VLP)
-
(arXiv preprint 2023) mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video, Haiyang Xu et al. [Paper] [Code]
- 📚 Downstream Tasks:
- [Vision Only] Video Action Recognition, Image Classification, Object Detection and Segmentation
- [Language Only] Natural Language Understanding, Natural Language Generation
- [Video-Text] Text-to-Video Retrieval, Video Question Answering, Video Captioning
- [Image-Text] Image-Text Retrieval, Visual Question Answering, Image Captioning, Visual Grounding
- 📚 Downstream Tasks:
-
(EMNLP 2022) FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning, Suvir Mirchandani et al. [Paper]
- 📚 Downstream Tasks: Image-to-Text Retrieval & Text-to-Image Retrieval, Image Retrieval with Text Feedback, Category Recognition & Subcategory Recognition, Image Captioning, Relative Image Captioning
-
(arXiv preprint 2022) PaLI: A Jointly-Scaled Multilingual Language-Image Model, Xi Chen et al. [Paper]
- 📚 Downstream Tasks: Image Captioning, Visual Question Answering (VQA), Language-understanding Capabilities, Zero-shot Image Classification
-
⭐⭐(arXiv preprint 2022) Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks, Wenhui Wang et al. [Paper] [Code]
- 📚 【Visual-Language】Visual Question Answering (VQA), Visual Reasoning, Image Captioning, Image-Text Retrieval
- 📚 【Visual】Object Detection, nstance Segmentation, Semantic Segmentation, Image Classification
-
(ECCV 2022) Exploiting Unlabeled Data with Vision and Language Models for Object Detection, Shiyu Zhao et al. [Paper] [Code]
- 📚 Downstream Tasks: Open-vocabulary object detection, Semi-supervised object detection, Pseudo label generation
-
⭐⭐[CVPR 2022 Tutorial] Recent Advances in Vision-and-Language Pre-training [Project]
-
⭐⭐(arXiv preprint 2022) [💬Data Augmentation] MixGen: A New Multi-Modal Data Augmentation, Xiaoshuai Hao et al. [Paper]
- 📚 Downstream Tasks: Image-Text Retrieval, Visual Question Answering (VQA), Visual Grounding, Visual Reasoning, Visual Entailment
-
⭐⭐(ICML 2022) Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts, Yan Zeng et al. [Paper] [Code]
- 🚀 SOTA(2022/06/16): Cross-Modal Retrieval on COCO 2014 & Flickr30k, Visual Grounding on RefCOCO+ val & RefCOCO+ testA, RefCOCO+ testB
- 📚 Downstream Tasks: Image-Text Retrieval, Visual Question Answering (VQA), Natural Language for Visual Reasoning (NLVR2), Visual Grounding, Image Captioning
-
⭐⭐(arXiv preprint 2022) Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts, Basil Mustafa et al. [Paper] [Blog]
- 📌 LIMoE: The first large-scale multimodal mixture of experts models.
-
(CVPR 2022) Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment, Mingyang Zhou et al. [Paper] [Code]
- 📚 Downstream Tasks: Visual Question Answering(VQA), Natural Language for Visual reasoning(NLVR2), Visual Entailment, Referring Expression(RefCOCO+)
-
⭐(arXiv preprint 2022) One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code, Yong Dai et al. [Paper]
- 📚 Downstream Tasks: Text Classification, Automatic Speech Recognition, Text-to-Image Retrieval, Text-to-Video Retrieval, Text-to-Code Retrieval
-
(arXiv preprint 2022) Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework, Chunyu Xie et al. [Paper]
- 📚 Downstream Tasks: Image-text Retrieval, Chinese Image-text matching
-
(arXiv preprint 2022) Vision-Language Pre-Training with Triple Contrastive Learning, Jinyu Yang et al. [Paper] [Code]
- 📚 Downstream Tasks: Image-text Retrieval, Visual Question Answering, Visual Entailment, Visual Reasoning
-
(arXiv preprint 2022) MVP: Multi-Stage Vision-Language Pre-Training via Multi-Level Semantic Alignment, Zejun Li et al. [Paper]
- 📚 Downstream Tasks: Image-text Retrieval, Multi-Modal Classification, Visual Grounding
-
(arXiv preprint 2022) BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, Junnan Li et al. [Paper] [Code]
- 📚 Downstream Tasks: Image-text Retrieval, Image Captioning, Visual Question Answering, Visual Reasoning, Visual Dialog
-
(ICML 2021) ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim et al. [Paper]
- 📚 Downstream Tasks: Image Text Matching, Masked Language Modeling
-
-
2023
- (arXiv preprint 2023) Accountable Textual-Visual Chat Learns to Reject Human Instructions in Image Re-creation, Zhiwei Zhang et al. [Paper] [Project] [Code]
- (arXiv preprint 2023) Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models, Gen Luo et al. [Paper] [Project] [Code]
- ⭐⭐(arXiv preprint 2023) Any-to-Any Generation via Composable Diffusion, Zineng Tang et al. [Paper] [Project] [Code]
- 📚[Single-to-Single Generation] Text → Image, Audio → Image, Image → Video, Image → Audio, Audio → Text, Image → Text
- 📚[Multi-Outputs Joint Generation] Text → Video + Audio, Text → Text + Audio + Image, Text + Image → Text + Image
- 📚[Multiple Conditioning] Text + Audio → Image, Text + Image → Image, Text + Audio + Image → Image, Text + Audio → Video, Text + Image → Video, Video + Audio → Text, Image + Audio → Audio, Text + Image → Audio
- ⭐⭐(arXiv preprint 2023) mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality, Qinghao Ye et al. [Paper] [Demo] [Code]
- (arXiv preprint 2023) Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models, Zhiqiu Lin et al. [Paper] [Project] [Code]
-
2022
- (arXiv preprint 2022) [💬Visual Metaphors] MetaCLUE: Towards Comprehensive Visual Metaphors Research, Arjun R. Akula et al. [Paper] [Project]
- (arXiv preprint 2022) MM-SHAP: A Performance-agnostic Metric for Measuring Multimodal Contributions in Vision and Language Models & Tasks, Letitia Parcalabescu et al. [Paper] [Code]
- (arXiv preprint 2022) Versatile Diffusion: Text, Images and Variations All in One Diffusion Model, Xingqian Xu et al. [Paper] [Code] [Hugging Face]
- 📚 Downstream Tasks: Text-to-Image, Image-Variation, Image-to-Text, Disentanglement, Text+Image-Guided Generation, Editable I2T2I
- (Machine Intelligence Research) [💬Vision-language transformer] Masked Vision-Language Transformer in Fashion, Ge-Peng Ji et al. [Paper] [Code]
- (arXiv 2022) [💬Multimodal Modeling] MAMO: Masked Multimodal Modeling for Fine-Grained Vision-Language Representation Learning, Zijia Zhao et al. [Paper]
- (arXiv 2022) [💬Navigation] Iterative Vision-and-Language Navigation, Jacob Krantz et al. [Paper]
- (arXiv 2022) [💬Video Chapter Generation] Multi-modal Video Chapter Generation, Xiao Cao et al. [Paper]
- (arXiv 2022) [💬Visual Question Answering (VQA)] TAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation, Jun Wang et al. [Paper] [Code]
- (AI Ethics and Society 2022) [💬Multi-modal & Bias] American == White in Multimodal Language-and-Image AI, Robert Wolfe et al. [Paper]
- (Interspeech 2022) [💬Audio-Visual Speech Separation] Multi-Modal Multi-Correlation Learning for Audio-Visual Speech Separation, Xiaoyu Wang et al. [Paper]
- (arXiv preprint 2022) [💬Multi-modal for Recommendation] Personalized Showcases: Generating Multi-Modal Explanations for Recommendations, An Yan et al. [Paper]
- (CVPR 2022) [💬Video Synthesis] Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning, Ligong Han et al. [Paper] [Code] [Project]
- (NAACL 2022) [💬Dialogue State Tracking] Multimodal Dialogue State Tracking, Hung Le et al. [Paper]
- (arXiv preprint 2022) [💬Multi-modal Multi-task] MultiMAE: Multi-modal Multi-task Masked Autoencoders, Roman Bachmann et al. [Paper] [Code] [Project]
- (CVPR 2022) [💬Text-Video Retrieval] X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval, Satya Krishna Gorti et al. [Paper] [Code] [Project]
- (NAACL 2022 2022) [💬Visual Commonsense] Visual Commonsense in Pretrained Unimodal and Multimodal Models, Chenyu Zhang et al. [Paper] [Code]
- (arXiv preprint 2022) [💬Pretraining framework] i-Code: An Integrative and Composable Multimodal Learning Framework, Ziyi Yang et al. [Paper]
- (CVPR 2022) [💬Food Retrieval] Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval, Mustafa Shukor et al. [Paper] [Code]
- (arXiv preprint 2022) [💬Image+Videos+3D Data Recognition] Omnivore: A Single Model for Many Visual Modalities, Rohit Girdhar et al. [Paper] [Code] [Project]
- (arXiv preprint 2022) [💬Hyper-text Language-image Model] CM3: A Causal Masked Multimodal Model of the Internet, Armen Aghajanyan et al. [Paper]
-
2021
- (arXiv preprint 2021) [💬Visual Synthesis] NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion, Chenfei Wu et al. [Paper] [Code]
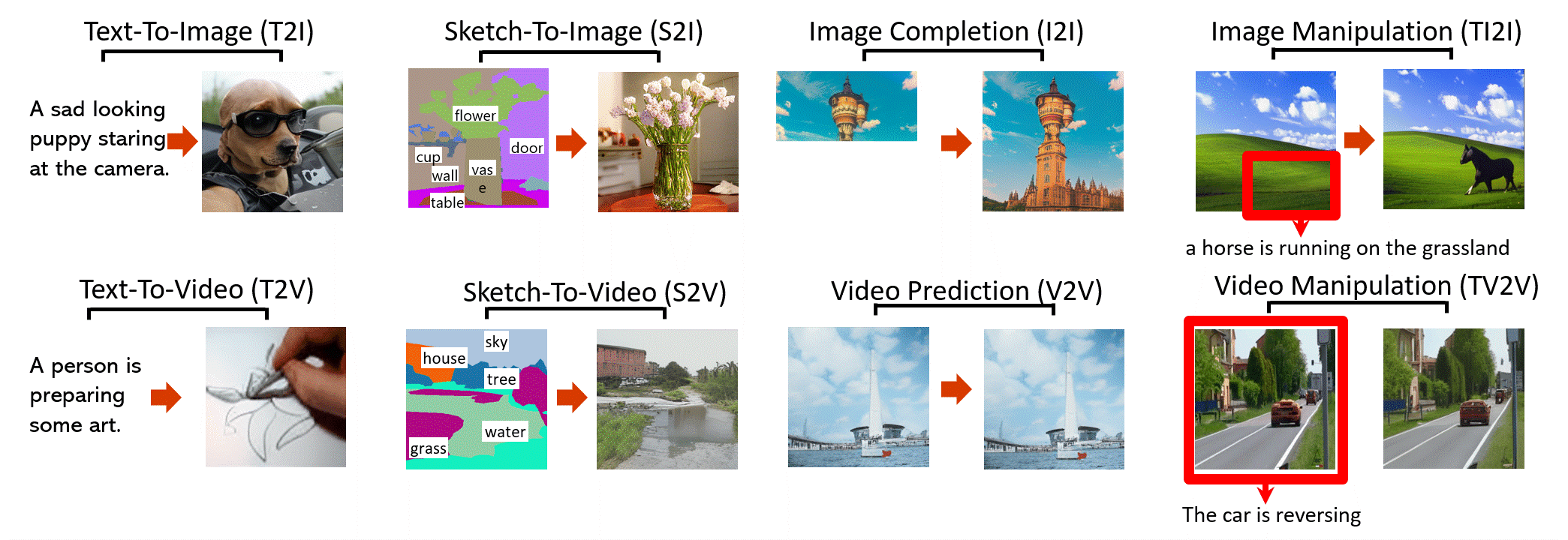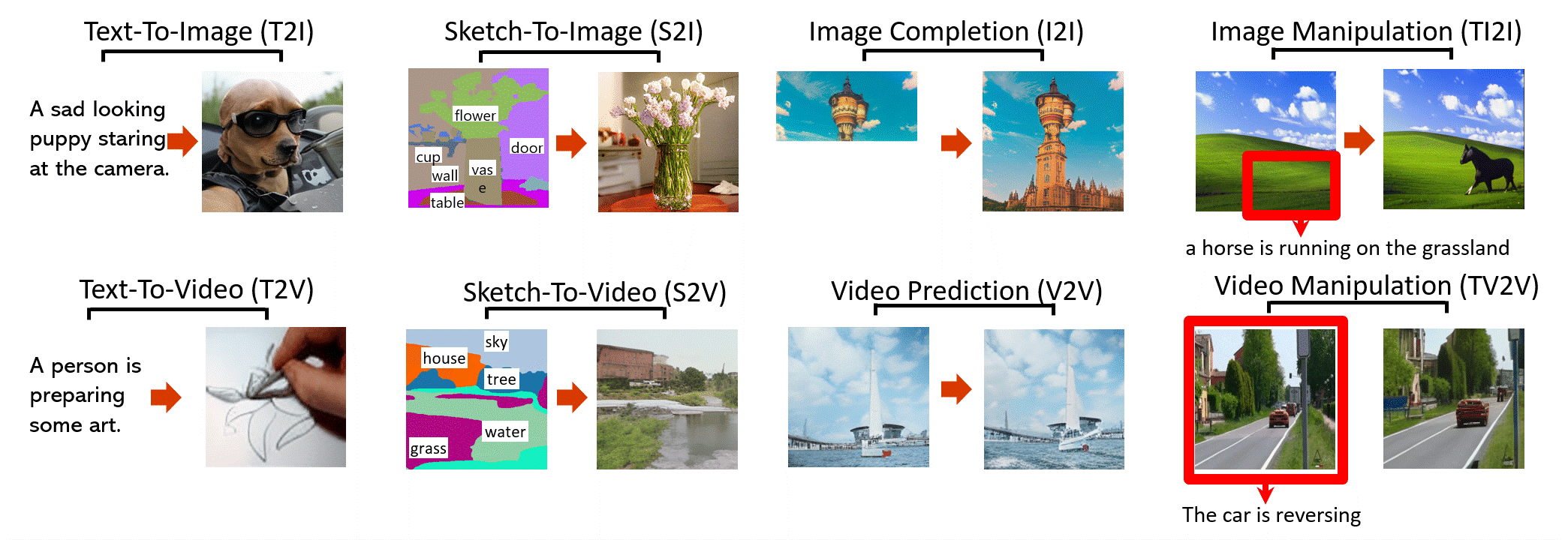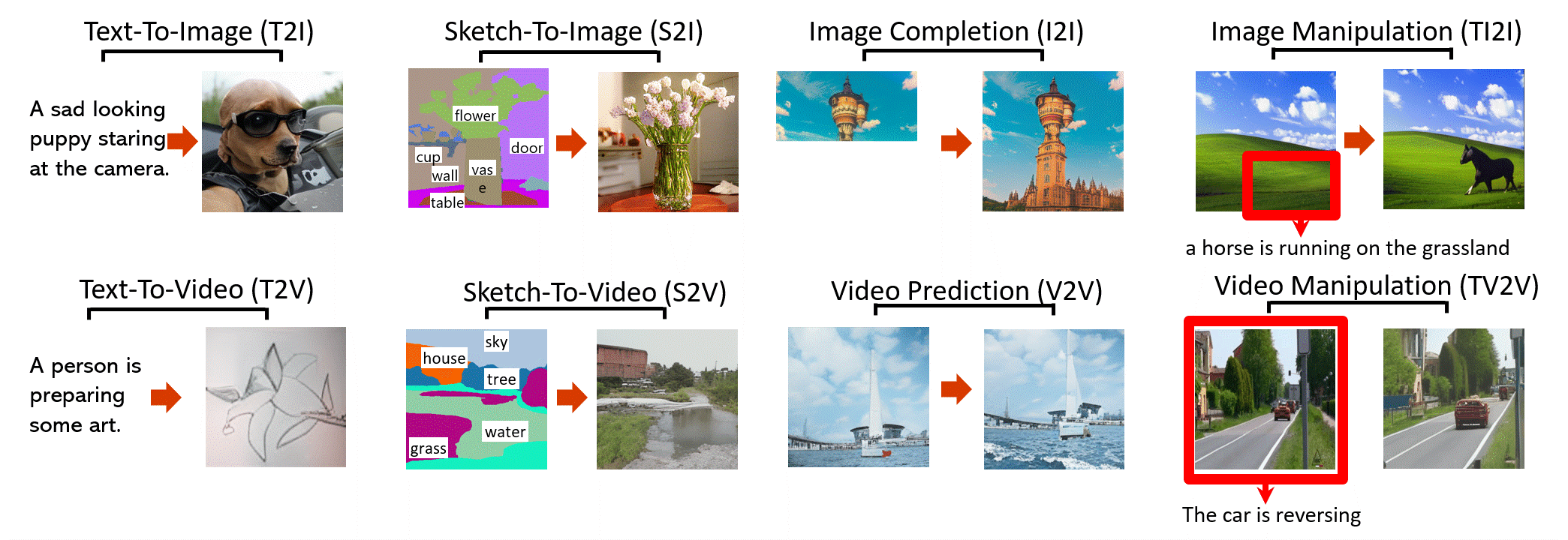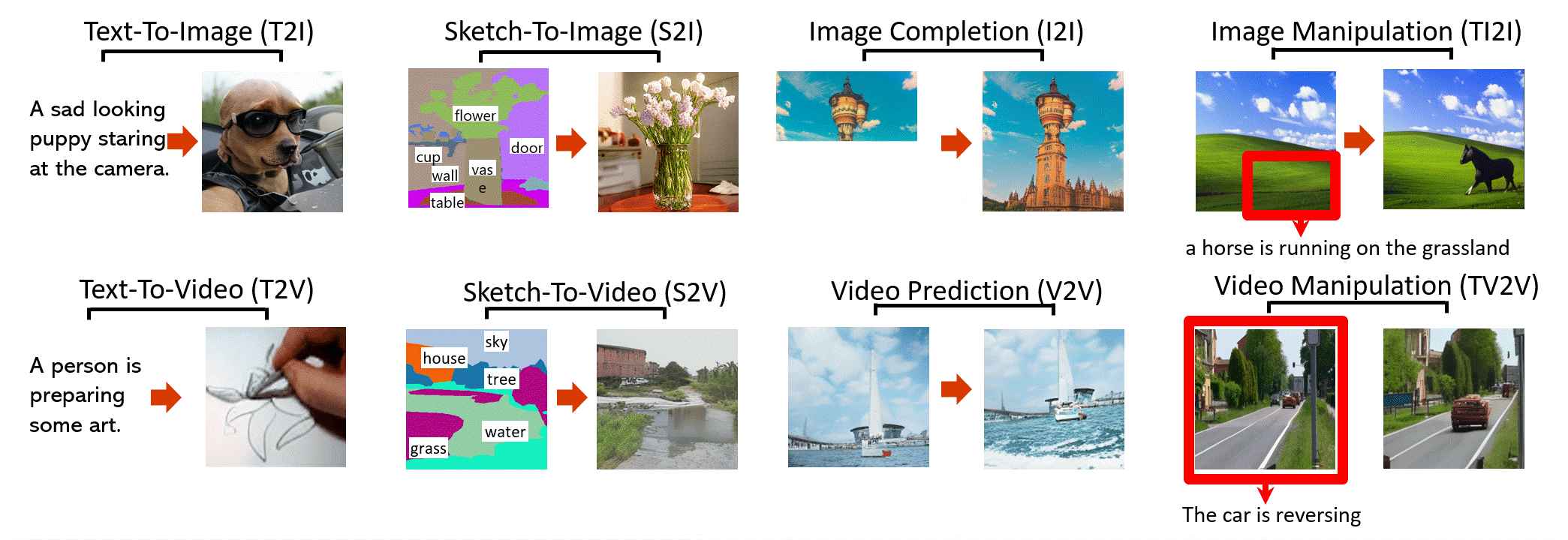
(From: https://github.com/microsoft/NUWA [2021/11/30])
- (ICCV 2021) [💬Video-Text Alignment] TACo: Token-aware Cascade Contrastive Learning for Video-Text Alignment, Jianwei Yang et al. [Paper]
- (arXiv preprint 2021) [💬Class-agnostic Object Detection] Multi-modal Transformers Excel at Class-agnostic Object Detection, Muhammad Maaz et al. [Paper] [Code]
- (ACMMM 2021) [💬Video-Text Retrieval] HANet: Hierarchical Alignment Networks for Video-Text Retrieval, Peng Wu et al. [Paper] [Code]
- (ICCV 2021) [💬Video Recognition] AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition, Rameswar Panda et al. [Paper] [Project] [Code]
- (ICCV 2021) [💬Video Representation] CrossCLR: Cross-modal Contrastive Learning For Multi-modal Video Representations, Mohammadreza Zolfaghari et al. [Paper]
- (ICCV 2021 Oral) [💬Text-guided Image Manipulation] StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery, Or Patashnik et al. [Paper] [Code] [Play]
- (ICCV 2021) [💬Facial Editing] Talk-to-Edit: Fine-Grained Facial Editing via Dialog, Yuming Jiang et al. [Paper] [Code] [Project] [Dataset Project] [Dataset(CelebA-Dialog Dataset)]
- (arXiv preprint 2021) [💬Video Action Recognition] ActionCLIP: A New Paradigm for Video Action Recognition, Mengmeng Wang et al. [Paper]
- (arXiv preprint 2021) [💬Visual Synthesis] NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion, Chenfei Wu et al. [Paper] [Code]
-
2020

-
Yutong ZHOU in Interaction Laboratory, Ritsumeikan University. ଘ(੭*ˊᵕˋ)੭
-
If you have any question, please feel free to contact Yutong ZHOU (E-mail: zhou@i.ci.ritsumei.ac.jp).