STU-Net: Scalable and Transferable Medical Image Segmentation Models Empowered by Large-Scale Supervised Pre-training
Ziyan Huang, Haoyu Wang, Zhongying Deng, Jin Ye, Yanzhou Su, Hui Sun, Junjun He, Yun Gu, Lixu Gu, Shaoting Zhang, Yu Qiao
[Apr. 13, 2023] [arXiv, 2023]
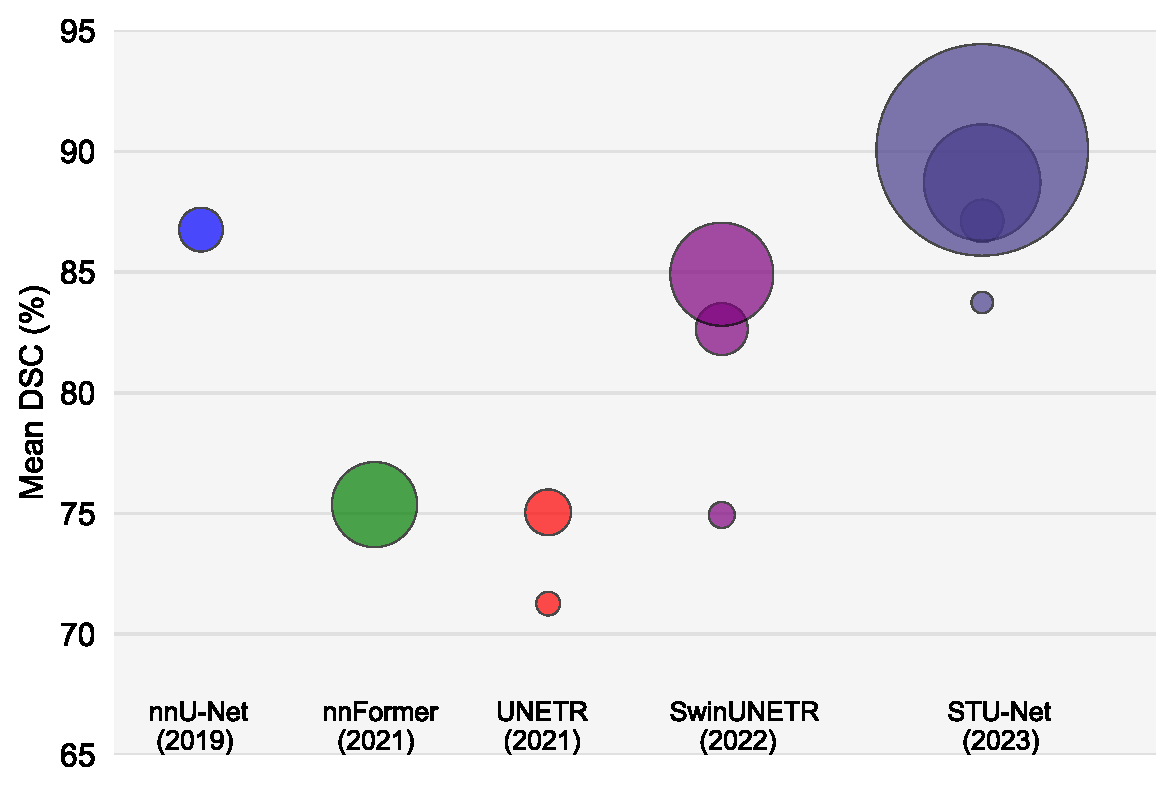

- Scalability: STU-Net is designed for scalability, offering models of various sizes (S, B, L, H), including STU-Net-H, the largest medical image segmentation model to date with 1.4B parameters.
- Transferability: STU-Net is pre-trained on a large-scale TotalSegmentator dataset (>100k annotations) and is capable of being fine-tuned for various downstream tasks.
- Based on nnU-Net: Built upon the widely recognized nnUNet framework, STU-Net provides a robust and validated foundation for medical image segmentation.
Large-scale models pre-trained on large-scale datasets have profoundly advanced the development of deep learning. However, the state-of-the-art models for medical image segmentation are still small-scale, with their parameters only in the tens of millions. Further scaling them up to higher orders of magnitude is rarely explored. An overarching goal of exploring large-scale models is to train them on large-scale medical segmentation datasets for better transfer capacities. In this work, we design a series of Scalable and Transferable U-Net (STU-Net) models, with parameter sizes ranging from 14 million to 1.4 billion. Notably, the 1.4B STU-Net is the largest medical image segmentation model to date. Our STU-Net is based on nnU-Net framework due to its popularity and impressive performance. We first refine the default convolutional blocks in nnU-Net to make them scalable. Then, we empirically evaluate different scaling combinations of network depth and width, discovering that it is optimal to scale model depth and width together. We train our scalable STU-Net models on a large-scale TotalSegmentator dataset and find that increasing model size brings a stronger performance gain. This observation reveals that a large model is promising in medical image segmentation. Furthermore, we evaluate the transferability of our model on 14 downstream datasets for direct inference and 3 datasets for further fine-tuning, covering various modalities and segmentation targets. We observe good performance of our pre-trained model in both direct inference and fine-tuning.

With an increase in model size, the segmentation performance on large-scale datasets improves. Furthermore, larger models demonstrate greater data efficiency in medical image segmentation compared to their smaller counterparts.

With an increase in model size, universal models become capable of concurrently segmenting numerous categories, exhibiting significant performance advancements.

With an increase in model size, models trained on large-scale datasets exhibit stronger performance when directly inferring downstream tasks.

With an increase in model size, our STU-Net models pre-trained on the large-scale dataset, TotalSegmentator, demonstrate enhanced performance on downstream tasks, markedly surpassing models trained from scratch.
We use TotalSegmentator dataset which contains 1204 images with 104 anatomical structures (consisting of 27 organs, 59 bones, 10 muscles and 8 vessels) for pre-training and 3 MICCAI 2022 challenge datasets as the downstream tasks for further fine-tuning.
torch==1.10
nnUNet==1.7.0
torchinfo
Our models are built based on nnUNet V1. Please ensure that you meet the requirements of nnUNet.
git clone https://github.com/Ziyan-Huang/STU-Net.git
cd nnUNet-1.7.1
pip install -e .
If you have installed nnUNetv1 already. You can just copy the following files in this repo to your nnUNet repository.
copy /network_training/* nnunet/training/network_training/
copy /network_architecture/* nnunet/network_architecture/
copy run_finetuning.py nnunet/run/
These models are trained on TotalSegmentator dataset by 4000 epochs with mirror data augmentation
| Model Name | Crop Size | #Params | FLOPs | Download Link |
|---|---|---|---|---|
| STU-Net-S | 128x128x128 | 14.6M | 0.13T | Baidu Netdisk | Google Drive |
| STU-Net-B | 128x128x128 | 58.26M | 0.51T | Baidu Netdisk | Google Drive |
| STU-Net-L | 128x128x128 | 440.30M | 3.81T | Baidu Netdisk | Google Drive |
| STU-Net-H | 128x128x128 | 1457.33M | 12.60T | Baidu Netdisk | Google Drive |
To perform fine-tuning on downstream tasks, use the following command with the base model as an example:
python run_finetuning.py 3d_fullres STUNetTrainer_base_ft TASKID FOLD -pretrained_weights MODEL
Please note that you may need to adjust the learning rate according to the specific downstream task. To do this, modify the learning rate in the corresponding Trainer (e.g., STUNetTrainer_base_ft) for the task.
To use our trained models to conduct inference on CT images, please first organize the file structures in your RESULTS_FOLDER/nnUNet/3d_fullres/ as follows:
- Task101_TotalSegmentator/
- STUNetTrainer_small__nnUNetPlansv2.1/
- plans.pkl
- fold_0/
- small_ep4k.model
- small_ep4k.model.pkl
- STUNetTrainer_base__nnUNetPlansv2.1/
- plans.pkl
- fold_0/
- base_ep4k.model
- base_ep4k.model.pkl
- STUNetTrainer_large__nnUNetPlansv2.1/
- plans.pkl
- fold_0/
- large_ep4k.model
- large_ep4k.model.pkl
- STUNetTrainer_huge__nnUNetPlansv2.1/
- plans.pkl
- fold_0/
- huge_ep4k.model
- huge_ep4k.model.pkl
These pickle files can be found in the plan_files directory within this repository. You can download the models from the provided paths above and set TASKID and TASK_NAME according to your preferences.
To conduct inference, you can use following command (base model for example):
nnUNet_predict -i INPUT_PATH -o OUTPUT_PATH -t 101 -m 3d_fullres -f 0 -tr STUNetTrainer_base -chk base_ep4k
For much faster inference speed with minimal performance loss, it is recommended to use the following command:
nnUNet_predict -i INPUT_PATH -o OUTPUT_PATH -t 101 -m 3d_fullres -f 0 -tr STUNetTrainer_base -chk base_ep4k --mode fast --disable_tta
The categories corresponding to the label values can be found in the label_orders file within our repository (please note that this differs from the official TotalSegmentator version).
If you have any question, feel free to contact ziyanhuang@sjtu.edu.cn.
This project is under the Apache License 2.0 license. See LICENSE for details.
Our code is based on the nnU-Net framework.
If you find this repository useful, please consider citing our paper:
@article{huang2023stu,
title={STU-Net: Scalable and Transferable Medical Image Segmentation Models Empowered by Large-Scale Supervised Pre-training},
author={Huang, Ziyan and Wang, Haoyu and Deng, Zhongying and Ye, Jin and Su, Yanzhou and Sun, Hui and He, Junjun and Gu, Yun and Gu, Lixu and Zhang, Shaoting and Qiao, Yu},
journal={arXiv preprint arXiv:2304.06716},
year={2023}
}