ccbrowse is an open source web application for browsing data from the CALIPSO and CloudSat satellites.
It is comprised of a web application and a backend for importing HDF4 (CALIPSO) and HDF-EOS2 (CloudSat) product files. An example ccbrowse deployment is available at browse.ccplot.org.
Note: As of version 0.8.0, a new storage driver fileref is the default. Importing is much faster and takes much less space. You might want to start with a new repository if migrating from a previous version. Otherwise your current storage driver as defined in the repository configuration is used.
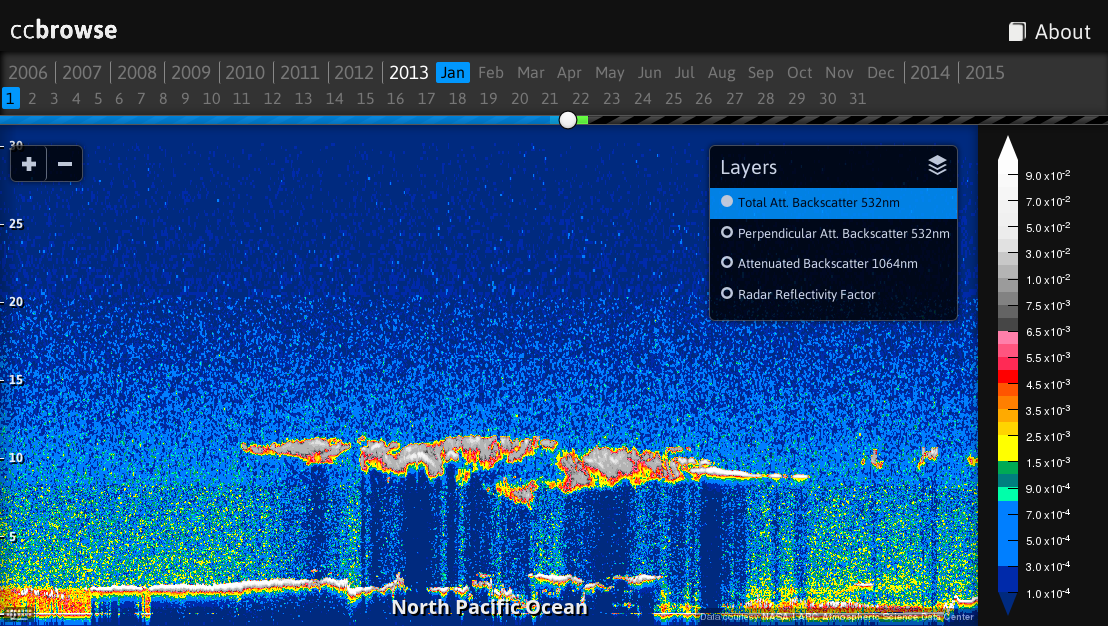
CALIPSO:
- CALIPSO Level 1 Profile
- Total Attenuated Backscatter 532 nm
- Perpendicular Attenuated Backscatter 532 nm
- Attenuated Backscatter 1064 nm
CloudSat:
- CloudSat 2B-GEOPROF:
- Radar Reflectivity Factor
ccbrowse can be installed on Linux. Other operating systems are currently not supported.
On Debian-based distributions (e.g. Ubuntu and Devuan), install system dependencies with:
apt install libhdf4-dev libhdfeos-dev libgeos-dev sqlite3 python3 python3-dev python3-setuptools cython3 pipx gdal-bin ronnInstall ccbrowse and the required package bintrees:
pipx install ccbrowse
pipx runpip ccbrowse install https://github.com/mozman/bintrees/archive/refs/tags/v2.2.0.zip
Make sure that the directory $HOME/.local/bin is in the PATH environmental
variable if not already, for example by adding PATH="$HOME/.local/bin:$PATH"
to ~/.profile.
A new ccbrowse repository repo can be created with:
ccbrowse create repo
cd repoThis will create a directory containing a profile specification, a
configuration file, file reference database, tile storage and cache. Next, you
import data to be displayed. Download CALIPSO Level 1B product HDF files from
NASA Earthdata or CloudSat 2B-GEOPROF product
HDF-EOS2 files from CloudSat DPC.
Choose the primary satellite in profile.json:
"primary": "calipso"The choices are calipso or cloudsat. The primary satellite data need to
be imported first for any given time period for time synchronization to work.
The setting should not be changed after any data have been imported.
To import product files:
cd repo
ccbrowse import TYPE FILE...where TYPE is calipso or cloudsat and FILE is a filesystem path to an HDF4
or HDF-EOS2 file. For example:
ccbrowse import calipso CAL_LID_L1-ValStage1-V3-01.2008-04-30T23-57-40ZN.hdfWhen the sqlite or filesystem storage
drivers are used (not the default), it is possible to import only a certain
layer or a zoom level with the -l or -z options. For example:
ccbrowse import -l calipso532 -z 2 calipso CAL_LID_L1-ValStage1-V3-01.2008-04-30T23-57-40ZN.hdfThis will generate tiles for the layer calipso532 and zoom level 2.
A soft (default) and a hard (option --hard) import are possible. The soft
import registers files or tiles by reference. The data are read and
interpolated on demand by the server. The hard import stores interpolated data
in tiles during the import. The hard import is slower during import but faster
during serving, and uses more space.
Finally, run the server with:
ccbrowse serverThis will make ccbrowse available in a web browser at http://localhost:8080/.
If you encounter any issues, file a bug report or post to the mailing list.
By default, the server listens on the port 8080 on localhost for incoming HTTP connections, but you can change that by supplying an address and port as an argument. For example:
ccbrowse server 192.168.0.1:8000To enable debugging mode, use the -d switch. Normally, this should be used
with the auto type of server backend to see messages on the console. This
will cause the server to respond with detailed messages should an error occur.
ccbrowse server -d -s auto
Other command line options:
-c CONFIG Configuration file (default: config.json)
-s SERVER Server backend or "help" for a list of options (default: gunicorn)
-w WORKERS Number of server backend workers (default: 10)
For a production deployment, it is recommended to start ccbrowse through
the operating system init system. Below is an example how to create a new
operating system user ccbrowse, install ccbrowse in this user's home
directory, and register a new system service to run ccbrowse on system start:
adduser --system --group --shell /bin/bash ccbrowse
mkdir /var/log/ccbrowse
chown ccbrowse:ccbrowse /var/log/ccbrowse
su - ccbrowse
pipx install ccbrowse
pipx runpip ccbrowse install https://github.com/mozman/bintrees/archive/refs/tags/v2.2.0.zip
ccbrowse create repo
cd repo
# Edit config.json. Change log to "/var/log/ccbrowse/error.log" and accesslog
# to "/var/log/ccbrowse/access.log".
exit
# For systemd based operating systems (e.g. Ubuntu or Debian):
cp ~ccbrowse/.local/lib/python*/site-packages/ccbrowse/init-scripts/systemd /etc/systemd/system/ccbrowse.service
systemctl enable ccbrowse.service
service ccbrowse start
# For init based operating systems (e.g. Devuan):
cp ~ccbrowse/.local/lib/python*/site-packages/ccbrowse/init-scripts/init /etc/init.d/ccbrowse
update-rc.d ccbrowse defaults
service ccbrowse startTo import data:
su - ccbrowse
cd repo
ccbrowse import ...
exit
service ccbrowse restartIn order to make ccbrowse available on a public domain, you can deploy an HTTP server such as nginx, and use this example virtual server configuration:
server {
listen 80;
listen [::]:80 default ipv6only=on;
server_name your.domain;
access_log /var/log/nginx/ccbrowse.access.log;
location / {
proxy_pass http://localhost:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
replacing your.domain with the desired domain name.
The ccbrowse repository is a directory that holds the profile specification, the configuration, imported file references or tiles and cache. Here is a list of files in a typical ccbrowse repository:
cache Tile cache
colormaps Custom colormaps
layers Layer data
config.json Repository configuration file
fileref.sqlite Fileref storage database
profile.json Profile specification
wsgi.py WSGI module
README README file
When you import a product file, it is stored in a storage. Depending on the
configuration, either a reference to the file is saved in the fileref database,
or references to the file are stored in tiles (soft import) in layers, or
tile data are stored in tiles in layers (hard import). If import is done by
file or tile references, tiles are generated on demand by the server. The raw
data are split and interpolated into tiles of 256×256 px. When tiles are
requested from the server, a chosen colormap is applied on them, and the
resulting images are saved in cache.
How tiles and images are stored is configurable. By default references to files are stored in the fileref database by the fileref storage. A second option is the SQLite storage, which stores references to the file (soft import) or interpolated data (hard import) in tiles in a number of SQLite databases, sharded (split) by the x-coordinate in order to avoid overly large database files and large number of files in file system directories. A third option is the filesystem storage, which does the same, but tiles are stored in individual files. This is suitable for testing purposes, but does not scale well to more than several product files with typical file systems.
The repository configuration is defined in config.json, e.g.:
"server": "gunicorn",
"workers": 10,
"log": null,
"loglevel": "info",
"accesslog": null,
"host": "localhost",
"port": 8080,
"debug": false,
"profile": "profile.json",
"colormaps": "colormaps",
"cache": {
"driver": "htree",
[...]
}
"storage": [
{
"driver": "fileref",
"requires": ["layer", "zoom", "x", "z"],
[...]
},
[...]
]
The configuration options are:
server Server backend (default: gunicorn)
workers Number of server backend workers (default: 10)
log Log file or null for none (default: null)
loglevel Log level: debug, info, warning, error, critical
(default: info)
accesslog Access log file or null for none (default: null)
host Hostname to listen on (default: localhost)
port Port to listen on (default: 8080)
debug Enable server debugging (default: false)
profile Path to profile.json (default: profile.json)
colormaps Directory containing colormap files (default: colormaps)
cache Server cache (permanent) storage configuration
driver Storage driver name
[option]... Storage configuration options
storage List of tile storage definitions
[storage] Storage configuration
requires List of required parameters
store_requires List of required parameters for storing tiles
retrieve_requires List of required parameters for retrieving tiles
driver Storage driver name
[option]... Storage configuration options
[storage]...
The storage configuration options are documented in a later section.
For a list of server backends, use ccbrowse -s help.
The profile specification defines what zoom levels and layers are available and how to access them. This information is needed by the importers, so that they know how to cut products into tiles, and by the web application, so that it knows how to present layers.
A sample profile.json:
{
"name": "A-Train",
"primary": "calipso",
"origin": ["2006-01-01 00:00:00", 0],
"prefix": "",
"zoom":
{
"0":
{
"width": 131072,
"height": 65536
},
[...]
},
"layers": {
"calipso532":
{
"format": "png",
"type": "float32",
"dimensions": "xz",
"units": "km<sup>-1</sup> sr<sup>-1</sup>",
"title": "Total Att. Backscatter 532nm",
"src": "layers/calipso532/{zoom}/{x},{z}.png",
"availability": "layers/calipso532/availability.json",
"attribution": "Data courtesy <a href=\"http://eosweb.larc.nasa.gov/PRODOCS/calipso/table_calipso.html\">NASA LARC Atmospheric Science Data Center</a>",
"colormap": "colormaps/calipso-backscatter.json"
},
[...]
"geography":
{
"format": "json",
"type": "geojson",
"title": "Geography",
"src": "layers/geography.json"
},
[...]
}
}
We can see a number of things in this profile specification:
-
It defines a profile called
A-Train. -
The primary satellite is
calipso. This means that CloudSat data will be synchronized to CALIPSO. -
The x-axis begins at midnight 1st January 2006, and the z-axis begins at an altitude of 0 m.
-
The lowest zoom level (
0) has tiles of 131072 ms in width and 65536 m in height (remember that tiles always have a fixed size of 256×256 px, so this determines the zoom factor and aspect ratio). -
There is a two-dimensional (
xz) layer calledcalipso532. Its full name is "Total Att. Backscatter 532nm" and has units of km-1.sr-1. Data in this layer is rendered with thecolormaps/calipso-backscatter.jsoncolormap. -
There is a layer called
geography, which does not have any dimensions (it is a single GeoJSON file). This is because it holds information about countries and marine areas, which is common for all x–z tiles.
The structure of the profile specification is as follows:
name Name of the profile
primary Primary satellite ("calipso" or "cloudsat")
origin The physical coordinates of the origin of the system
As time in format "year-month-day hour:minute:second"
And altitude in meters
prefix uRL prefix (when hosting on http://your.domain/prefix/)
zoom List of zoom levels
0 Zoom level 0
width Tile width in milliseconds
height Tile height in meters
1 Zoom level 1
[...]
layers List of layers
[layer name] Short name of the layer (without white space)
format Tile format (png or json)
type Tile data type (float32 or geojson)
dimensions Layer dimensions
"xz" for two-dimensional layers
"x" for one-dimensional layers
"" for zero-dimensional layers (e.g. geography)
units Physical units of data
title Layer title
src Source URL
availability Layer availability
attribution Data attribution text displayed on the map
colormap Colormap for rendering images
[...]
As a user, you might wish to modify zoom level and origin, whereas you should not modify layers unless you developed you own import class, or you are not interested in importing certain layers (in which case you can remove them).
When modifying the profile specification, the tiles you have already imported remain unchanged. For example, if you modify zoom levels, the x–z coordinates would reference the wrong tiles. To avoid the situation, you should either modify the profile specification before you import any products, or modify the tiles in storage accordingly (which may be difficult).
You can safely change name, primary, prefix, layer title, units, and
colormap.
If you were to add a new layer to the profile specification, it would not
become supported by ccbrowse without an additional effort. The web application
would display its name in the selection of layers, but it could not retrieve
any data. For that, you have write an import class or extend an existing one,
which reads the relevant data from product files and returns an array of data
interpolated on a regular grid of 256×256 elements for each tile. You can find
instructions on how to do that in src/ccbrowse/products/product.py, and use
the existing import classes in the same directory as an example.
Internally, ccbrowse handles files and tiles as objects. A tile object is a simple list of parameters (key–value pairs), e.g.
{
"layer": "calipso532",
"zoom": 2,
"x": 7120,
"z": 0,
"raw_data": [...],
"format": "png",
[...]
}
The parameters include layer, zoom level, coordinates and data, in addition to all parameters defined in the profile specification under the particular layer.
Storing and retrieval of objects is done by storage drivers. Which storage
driver to use and its configuration is defined in the configuration file
config.json. You can modify the configuration in order to store tiles
in a location other that the default, or use a custom sharding.
The default storage is fileref, which stores file references. If more than
one storage is specified in the configuration file, they are used in a
sequence. For storing, the first storage for which the store_requires or
requires list is satisfied is selected. For retrieving, the first storage
which satisfies retrieve_requires or requires and has the tile is used.
store_requires and retrieve_requires take precedence over requires.
There are several storage drivers available.
This storage applies to files. It stores references to files in a SQLite database.
Example configuration:
{
"store_requires": ["ref"],
"retrieve_requires": ["layer", "zoom", "x", "z"],
"driver": "fileref",
"src": "fileref.sqlite"
}
Configuration options:
driver "fileref"
src Filesystem path of the database file
This storage applies to tiles. This is the simplest type of tile storage, when objects are stored in standalone files.
Example configuration:
{
"driver": "filesystem",
"requires": ["layer", "zoom", "x", "z", "format"],
"src": "layers/{layer}/{zoom}/{x},{z}.{format}"
}
Configuration options:
driver "filesystem"
src Filesystem path relative to the repository directory
This storage applies to tiles. Objects are stored as rows in a SQLite database.
Example configuration:
{
"driver": "sqlite",
"requires": ["layer", "zoom", "x", "z"],
"src": "layers/{layer}/{zoom}/{x-x%100000}.tiles",
"select": "SELECT raw_data, modified from tiles WHERE x={x} AND z={z}",
"insert": "INSERT OR REPLACE INTO tiles (x, z, raw_data, modified) VALUES ({x}, {z}, {raw_data}, strftime('%s'))",
"init": [
"CREATE TABLE tiles (x INT, z INT, raw_data BLOB, modified INT)",
"CREATE UNIQUE INDEX tiles_idx ON tiles (x, z)",
"CREATE INDEX tiles_modified_idx ON tiles (modified)"
]
}
Configuration options:
driver "sqlite"
src Filesystem path of the database file
select SQL query to retrieve object by its coordinates
insert SQL query to insert object
init List of SQL queries for initialization of an empty database
This storage applies to tiles and is normally used as tile cache. Objects are stored in a number of SQLite databases (chunks) according to their hash. Hash of an object is computed by applying SHA1 function on a key, where key is a string based on object parameters. The number of database files grows automatically in order to maintain a given maximum chunk size.
Example configuration:
{
"driver": "htree",
"chunk": "128MB",
"src": "cache/chunks/{'%02d'%bits}:{hash}.tiles",
"index": "cache/index.sqlite",
"lock": "cache/.lock",
"key": "{layer}/{zoom}/{x},{z};{sha1(colormap)}",
"hashlen": 5,
"select": "SELECT raw_data, modified from tiles WHERE layer={layer} AND zoom={zoom} AND x={x} AND z={z} AND colormap={sha1(colormap)}",
"insert": "INSERT INTO tiles (_id, _hash, layer, zoom, x, z, colormap, modified, raw_data) VALUES ({_id}, {_hash}, {layer}, {zoom}, {x}, {z}, {sha1(colormap)}, strftime('%s'), {raw_data})",
"init": [
"CREATE TABLE tiles (_id INT, _hash TEXT, layer TEXT, zoom INT, x INT, z INT, colormap TEXT, modified INT, raw_data BLOB)",
"CREATE INDEX tiles_id_idx ON tiles (_id)",
"CREATE INDEX tiles_idx ON tiles (layer, zoom, x, z)"
]
}
Configuration options:
driver "htree"
chunk Maximum chunk size, after which it is split into two
src Filesystem path to chunk
index Database holding index of chunks
lock Lock file
key Object key
hashlen Length of sha1 hash of key (more digits are discarded)
select SQL query to retrieve object from a chunk
insert SQL query to insert object into a chunk
init A list of SQL queries to initialize a new chunk
Following the example, when the storage is first created, all objects are being stored in single database file:
00:00000.tiles
where "00" before colon is the number of significant bits, and "00000" is the hash. The number of significant bits is 0, as all objects are stored in the same chunk.
When the database grows over 128MB, the database is split into two chunks:
01:00000.tiles
01:80000.tiles
The first is filled with objects whose first bit of hash is 0 (hash < 80000), and the second with those whose first bit of hash is 1 (hash >= 80000).
When the second chunk grows 128MB, it is split into two other chunks:
01:00000.tiles
02:80000.tiles
02:c0000.tiles
Now, first two bits of the hash are significant. For example, an object with
hash 720ec would go to the first database, 9e4b1 to the second and ee387
to the third. The number of chunks can increase in this fashion until the last
significant bit of the hash is reached.
The table in chunk is allowed to have an arbitrary name (here "tiles"), but two
columns are required by the HTree storage: _id and _hash, having the value
of the supplied _id and _hash parameters (respectively).
ccbrowse consists of two parts: a Python backend and a JavaScript web
application. The backend is responsible for importing product files and serving
tiles. The interface between the backend and the web application is defined by
profile.json. Data are interpolated onto a regular grid and saved as tiles of
256×256 px. In tile storage, tiles are stored as greyscale PNG images, with
every four adjacent 8-bit pixels coding one 32-bit float value, resulting in
images of 1024×256 px. The web application consists of a Python bottle server
and a JavaScript application running in the browser. The JavaScript application
uses the mapping framework Leaflet for
displaying tiles. Information for popups and location is fetched via JSON. The
server is responsible for serving static files, tiles, as well as applying a
given colormap. It also performs geocoding with the shapely library using
geographical data from Natural Earth.
Usage: ccbrowse COMMAND [ARGS]
ccbrowse COMMAND --help
ccbrowse --help
ccbrowse --version
Perform commands on a ccbrowse repository.
Available commands:
create create a new repository
import import a product file
server run the ccbrowse HTTP server
Optional arguments:
--help print this help information and exit
--version print the version number and exit
Use `ccbrowse COMMAND --help' for more information about a command.
Usage: ccbrowse create NAME
ccbrowse create --help
Create a new repository.
Positional arguments:
NAME name of the repository
Optional arguments:
--help print this help information and exit
Usage: ccbrowse import [OPTIONS] TYPE FILE...
ccbrowse import --help
Import data from FILE into profile specified in configuration file.
Positional arguments:
TYPE product type
FILE product file
Optional arguments:
-c FILE configuration file (default: config.json)
-j N number of parallel jobs (default: number of CPU cores)
-l LAYER import only specified profile layer
--overwrite overwrite existing tiles
-s print statistics
--skip skip tiles that exist
--hard hard import
--help print this help information and exit
-z ZOOM import only specified zoom level
Supported product types:
calipso
cloudsat
naturalearth
Usage: ccbrowse server [OPTIONS] [[HOST:]PORT]
ccbrowse server --help
Run the ccbrowse HTTP server.
Positional arguments:
HOST hostname (default: localhost)
PORT port (default: 8080)
Optional arguments:
-c FILE configuration file (default: config.json)
-d print debugging information
--help print this help information and exit
-s SERVER server backend or "help" to print a list of backends
-w WORKERS number of server backend workers
- Fixed installation on Python 3.11.
- Added installation notes about pipx.
- ccbrowse import: Improved parallelisation support and error reporting.
- Improved and fixed command help messages.
- Added manual pages.
- Atomic file writing in the filesystem storage.
- Minor improvements in the About page.
- Restrict satellite offset calculation to an average distance of 20 km.
- Support for printing version information in the ccbrowse command.
- Fixed help message in ccbrowse server.
- Removal of obsolete code.
- Improvements in the documentation.
- Minor code cleanup and improvements.
- New default fileref storage.
- Parallel importing.
- Fixed offset calculation.
- Fixed navigation bar years when switching between layers with different availability.
- Improved importing of CloudSat data.
- Fixed navigation tooltip overflow in Safari.
- Improved popup layout.
- Minor fixes in the documentation.
- Updated to the latest version of Leaflet.
- Fixed updating of y-axis on zoom.
- Fixed continuous array error on server side.
- Fixed UTC date parsing.
- Fixed initial map placement on Windows.
- Fixed running on Safari.
- Fixed globe if location is unknown.
- Added loading icon.
- Support for choosing a primary satellite (CloudSat or CALIPSO).
- Removed obsolete NASA ECHO service code.
- Transition from raster to SVG images for page elements and favicon.
- Embedded fonts.
- Fixed pointer events on map elements.
- Fixed context switching from About page.
- Fixed missing data warning appearing on page load.
- Globe showing the current location.
- Faster geocoding.
- Removed dependency on MooTools.
- Support for mobile.
- Fixed location bar.
- Fixed display of navigation panel days.
- Fixed progress indication in ccbrowse import.
- Fixed SysV init script.
- Support for reading CALIPSO product files converted to HDF5.
- Updated to a new version of the d3 library.
- Initial release.