RLeXplore is a unified, highly-modularized and plug-and-play toolkit that currently provides high-quality and reliable implementations of eight representative intrinsic reward algorithms. It used to be challenging to compare intrinsic reward algorithms due to various confounding factors, including distinct implementations, optimization strategies, and evaluation methodologies. Therefore, RLeXplore is designed to provide unified and standardized procedures for constructing, computing, and optimizing intrinsic reward modules.
The workflow of RLeXplore is illustrated as follows:

- with pip
recommended
Open a terminal and install rllte with pip:
conda create -n rllte python=3.8
pip install rllte-core - with git
Open a terminal and clone the repository from GitHub with git:
git clone https://github.com/RLE-Foundation/rllte.git
pip install -e .Now you can invoke the intrinsic reward module by:
from rllte.xplore.reward import ICM, RIDE, ...| Type | Modules |
|---|---|
| Count-based | PseudoCounts, RND, E3B |
| Curiosity-driven | ICM, Disagreement, RIDE |
| Memory-based | NGU |
| Information theory-based | RE3 |
Click the following links to get the code notebook:
- Quick Start
- RLeXplore with RLLTE
- RLeXplore with Stable-Baselines3
- RLeXplore with CleanRL
- Exploring Hybrid Intrinsic Rewards
- Custom Intrinsic Rewards
We have published a space using Weights & Biases (W&B) to store reusable experiment results on recognized benchmarks. The space link is: RLeXplore's W&B Space.

RLLTE's PPO+RLeXploreon SuperMarioBros:

-
RLLTE's PPO+RLeXploreon MiniGrid:- DoorKey-16×16
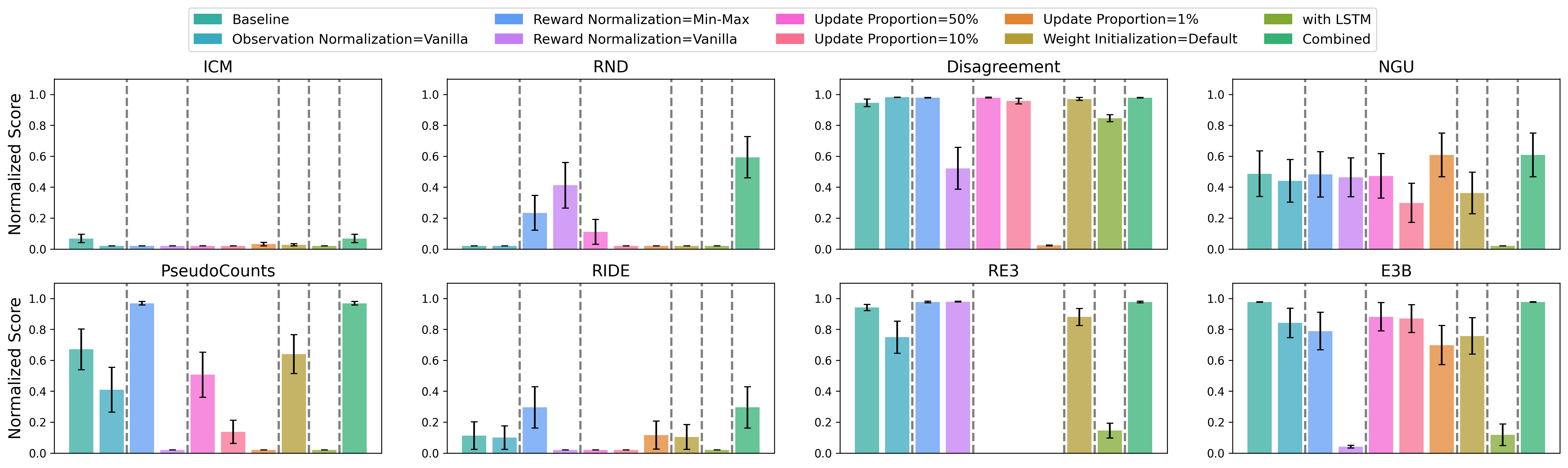
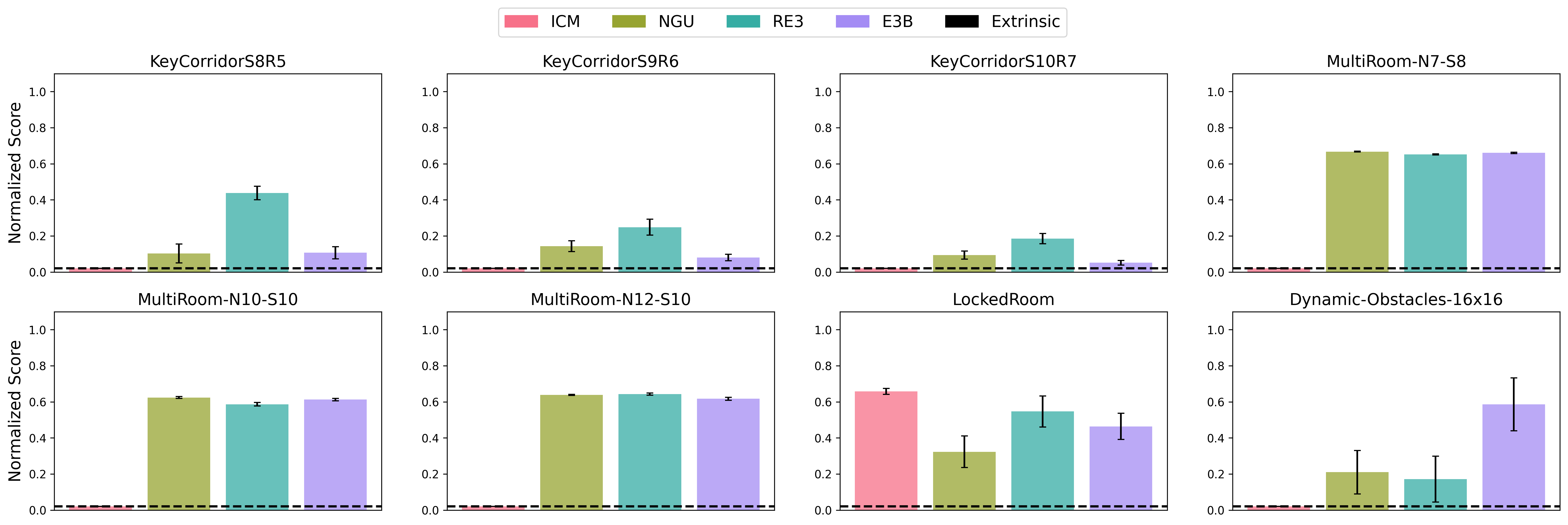
- KeyCorridorS8R5, KeyCorridorS9R6, KeyCorridorS10R7, MultiRoom-N7-S8, MultiRoom-N10-S10, MultiRoom-N12-S10, Dynamic-Obstacles-16x16, and LockedRoom
-
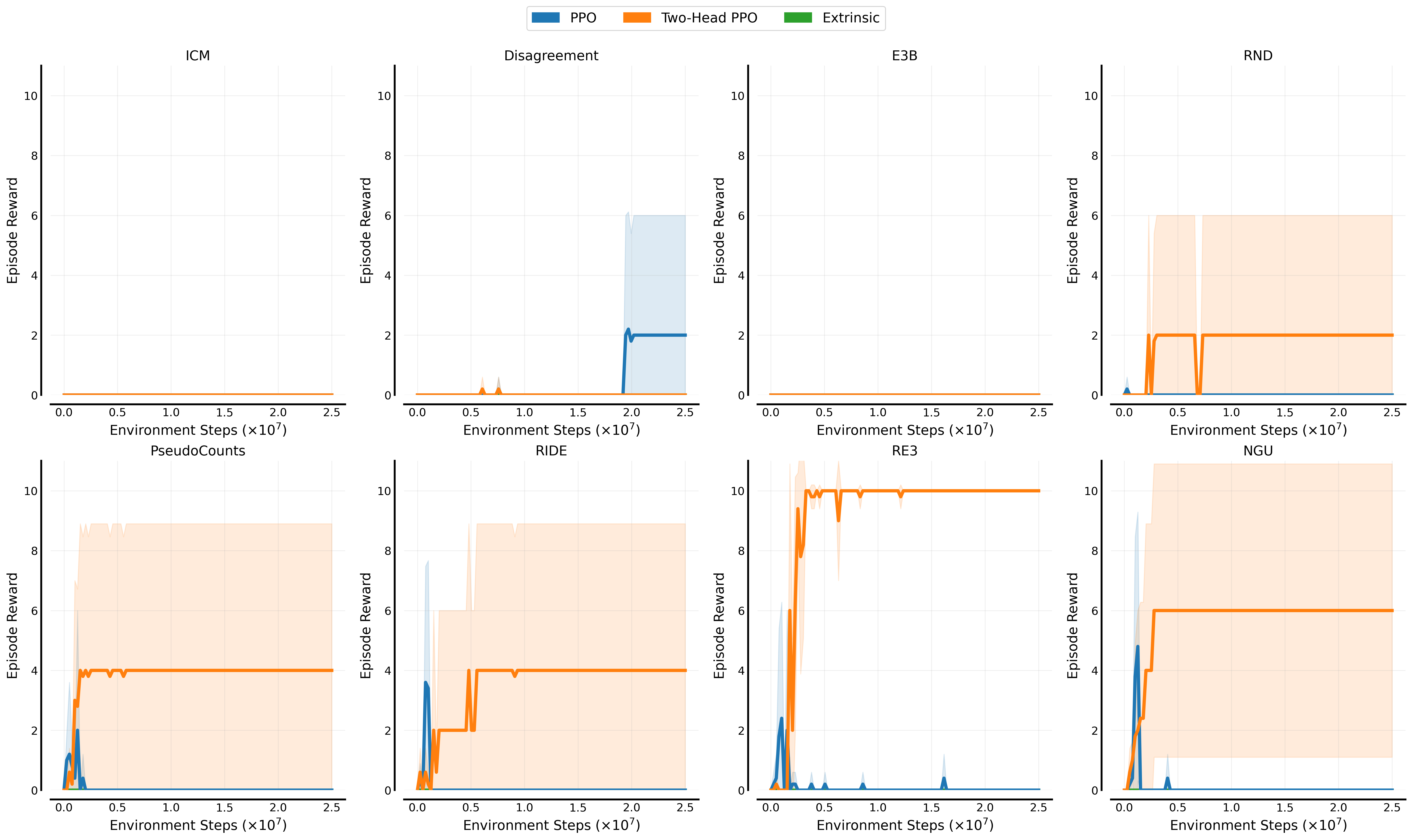
RLLTE's PPO+RLeXploreon Procgen-Maze:- Number of levels=1
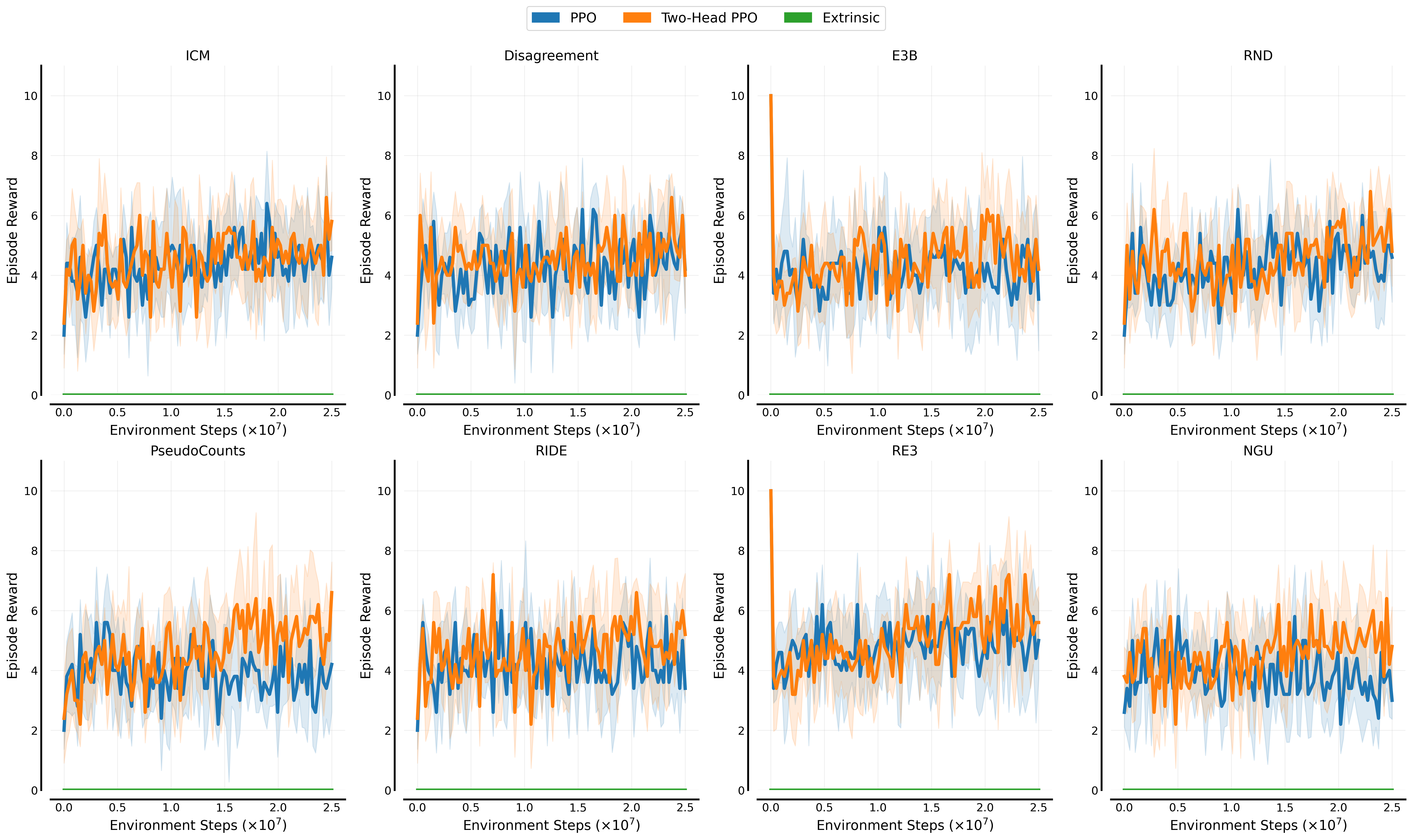
- Number of levels=200
-
RLLTE's PPO+RLeXploreon five hard-exploration tasks of ALE:




| Algorithm | Gravitar | MontezumaRevenge | PrivateEye | Seaquest | Venture |
|---|---|---|---|---|---|
| Extrinsic | 1060.19 | 42.83 | 88.37 | 942.37 | 391.73 |
| Disagreement | 689.12 | 0.00 | 33.23 | 6577.03 | 468.43 |
| E3B | 503.43 | 0.50 | 66.23 | 8690.65 | 0.80 |
| ICM | 194.71 | 31.14 | -27.50 | 2626.13 | 0.54 |
| PseudoCounts | 295.49 | 0.00 | 1076.74 | 668.96 | 1.03 |
| RE3 | 130.00 | 2.68 | 312.72 | 864.60 | 0.06 |
| RIDE | 452.53 | 0.00 | -1.40 | 1024.39 | 404.81 |
| RND | 835.57 | 160.22 | 45.85 | 5989.06 | 544.73 |
CleanRL's PPO+RLeXplore's RNDon Montezuma's Revenge:

RLLTE's SAC+RLeXploreon Ant-UMaze:

To cite this repository in publications:
@article{yuan_roger2024rlexplore,
title={RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning},
author={Yuan, Mingqi and Castanyer, Roger Creus and Li, Bo and Jin, Xin and Berseth, Glen and Zeng, Wenjun},
journal={arXiv preprint arXiv:2405.19548},
year={2024}
}