This repository serves as a record of my academic experience in CMSC848F during the Fall of 2023. It includes my paper reviews, solutions, and code submissions for projects. Each project is organized within its respective folder, complete with accompanying documentation and any necessary resources.
This 3D Computer Vision course provides a comprehensive journey through the principles and applications of three-dimensional visual data. It focuses on 5 key modules:
1. Background : This module covers fundamental concepts, including 2D - 3D basics, 2.5D, layered depth images, multi-plane images, voxels, meshes, point clouds, and implicit representations.
2. Classical Multi-view Geometry : This module includes learnining 3D Representations, Multiview Depth Estimation, Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM)
3. Single-View 3D : This module focuses on single-view 3D techniques. Students gain insight into single-view 3D representation methods, monocular depth estimation, and surface normal estimation.
4. 3D Scene Representations & Neural Rendering : Building on the fundamentals, this module explores advanced view synthesis techniques and implicit surface rendering approaches.
5. 3D Processing and Generation :This module helps develop proficiency in processing point clouds, covering classification, segmentation, and detection. Additionally, we delve into techniques for processing mesh representations, understanding generative models for 3D data, and exploring dynamic aspects of 3D data.
- Click here to access CMSC848f Projects directly.
- Click here to access outputs of all projects on my Website.
Project 1: Rendering with Pytorch3D
-
Learnings from Project 1:
-
Rendering First Mesh: Acquired a basic understanding of mesh rendering using PyTorch3D.
-
Practicing with Cameras: Created 360-degree gifs and set camera viewpoints for rendering.
-
Re-creating the Dolly Zoom: Successfully implemented the Dolly Zoom effect in PyTorch3D.

-
Practicing with Meshes: Created and rendered 3D shapes such as a tetrahedron and a cube.
-
Re-texturing a Mesh: Changed mesh colors based on vertex positions.
-
Camera Transformations: Implemented camera pose transformations for rendering.
-
Rendering Generic 3D Representations: Rendered point clouds and constructed them from RGB-D images. Parametrically generated and rendered point clouds.

-
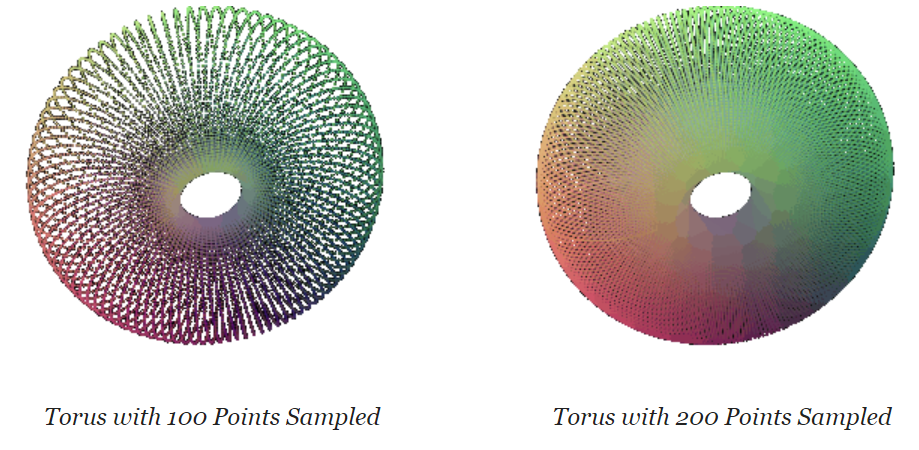
Implicit Surfaces: Utilized implicit functions to define surfaces and converted them to meshes. Rendered a torus mesh with an implicit function and discussed mesh vs. point cloud rendering trade-offs.

Project 2: Single View to 3D
-
-
Learnings from Project 2:
-
Exploring Loss Functions:
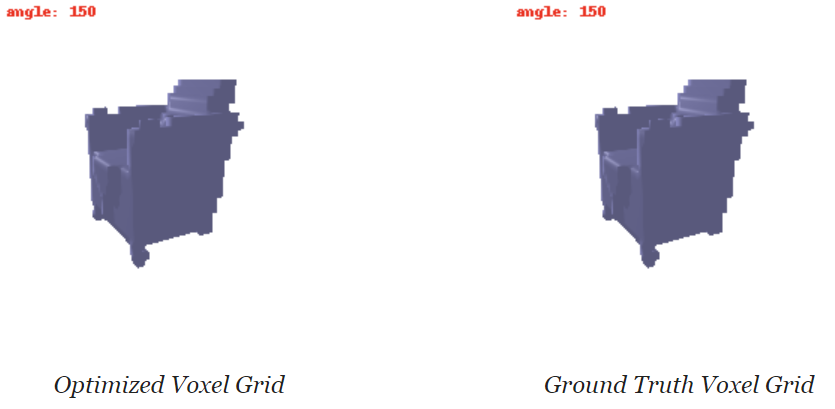
- Fitting a Voxel Grid: Understood and implemented binary cross-entropy loss for regressing to 3D binary voxel grids.
- Fitting a Point Cloud: Successfully implemented Chamfer loss for fitting 3D point clouds and wrote custom code for this purpose.

- Fitting a Mesh: Defined a smoothing loss for fitting a 3D mesh, utilizing pre-defined losses in the PyTorch library. <img src="reviews_and_presentations/outputs/a2_mesh.png" alt="dolly zoom" width=70%">
- Fitting a Voxel Grid: Understood and implemented binary cross-entropy loss for regressing to 3D binary voxel grids.
-
Reconstructing 3D from Single View:
- Designed an Image to Voxel Grid Model: Created a neural network to decode binary voxel grids, possibly modifying the provided decoder, and trained the single-view to voxel grid pipeline.
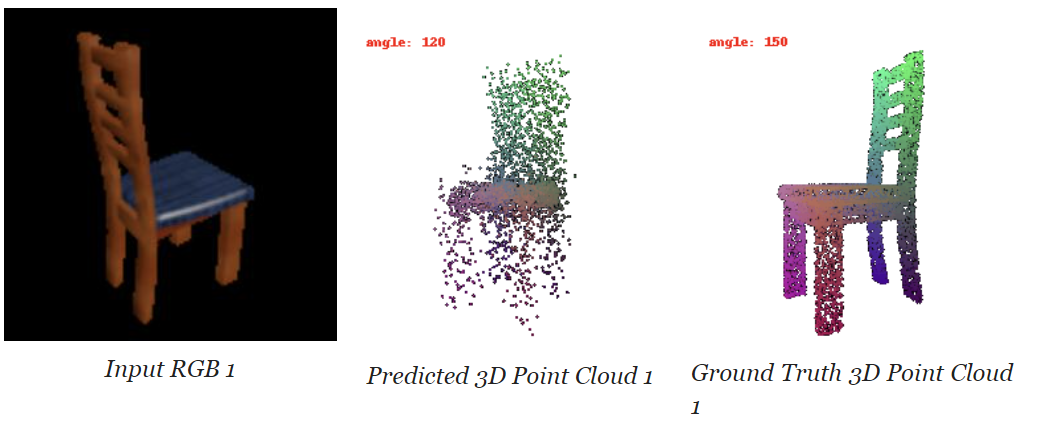
- Developed an Image to Point Cloud Model: Designed a neural network to decode point clouds, similar to voxel grid, and trained the single-view to point cloud pipeline.
- Defined an Image to Mesh Model: Developed a neural network to decode meshes, modified the provided decoder, and trained the single-view to mesh pipeline. Experimented with different mesh initializations.

- Conducted Quantitative Comparisons: Compared F1 scores of 3D reconstruction for meshes, point clouds, and voxel grids and justified the comparison with an intuitive explanation.
- Analyzed Effects of Hyperparameter Variations: Investigated the impact of varying hyperparameters, such as n_points, vox_size, w_chamfer, or initial mesh, on the model's performance.
- Interpreted My Model: Created insightful visualizations to understand what the learned model does and gained insights into its behavior. This included visualizing feature maps and encoder information.

-









These learnings encompass a wide range of topics related to 3D reconstruction from single-view RGB input, loss functions, neural network design, and hyperparameter tuning. Additionally, they include the use of PyTorch and PyTorch3D for implementing these concepts.
Project 3: Volume Rendering and Neural Radiance Fields
-
Learnings from Project 3:
-
Differentiable Volume Rendering:
-
Ray Sampling: Learned how to generate world space rays from camera positions and pixel coordinates using PyTorch3D.
-
Point Sampling: Implemented a stratified sampler to generate sample points along each ray, taking into account near and far distances. Explored visualization of sample points.
-
Volume Rendering: Implemented a volume renderer that evaluates a volume function at each sample point along a ray, aggregates these evaluations, and renders color and depth information. Explored volume density and color computations based on the emission-absorption model.
-
-
Optimizing a Basic Implicit Volume:
-
Random Ray Sampling: Implemented random ray sampling to optimize the position and side lengths of a 3D box. Explored the concept of training on a subset of rays to save memory.
-
Loss and Training: Replaced loss functions with Mean Squared Error (MSE) between predicted colors and ground truth colors (rgb_gt). Conducted training and reported the center and side lengths of the optimized box.
-
Visualization: Created a spiral rendering of the optimized volume and compared it with a reference gif.
-
-
Optimizing a Neural Radiance Field (NeRF):
-
NeRF Implementation: Implemented an implicit volume as a Multi-Layer Perceptron (MLP) to map 3D positions to volume density and color. Utilized ReLU activation for density and Sigmoid activation for color. Explored the use of Positional Encoding for improved quality.
-
Loss and Training: Wrote the loss function for training the NeRF model on RGB images. Explored data loading, training, and checkpointing. Trained NeRF on the lego bulldozer dataset.
-
Visualization: Trained a NeRF on a specific dataset and created a spiral rendering of the optimized volume. Reported the results and compared them to reference visuals.

-
-

These learnings encompass various aspects of differentiable volume rendering, 3D optimization, and the implementation of Neural Radiance Fields.
Project 4: Point Cloud Classification and Segmentation
-
Learnings from Project 4:
-
Classification Model Implementation:
- Developed an understanding of implementing a PointNet-based architecture for point cloud classification.
- Learned to define model structures, handling input points from multiple classes (chairs, vases, lamps).
- Explored model initialization, training, and testing procedures.

-
Segmentation Model Implementation:
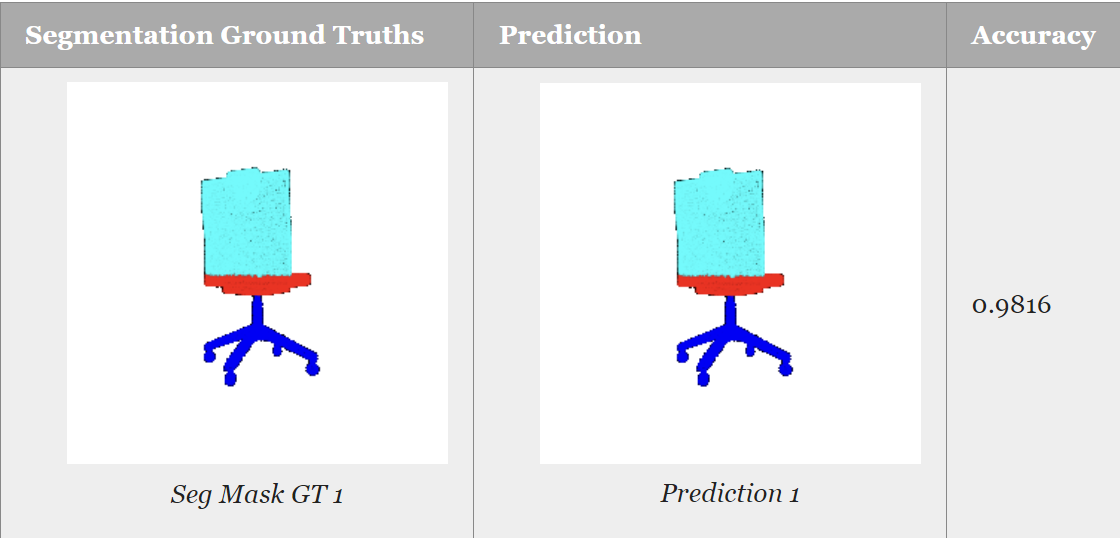
- Gained insights into implementing a PointNet-based architecture for point cloud segmentation.
- Defined the model structure for segmentation tasks focusing on chair objects.
- Executed model initialization, training, and segmentation result visualization.
-
Experimentation and Robustness Analysis:
- Conducted two robustness experiments to evaluate the model's performance under different conditions.
- Explored rotation of input point clouds by 15, 45, 90 degrees and varying the number of points per object by 10000, 5000, 1000.
- Analyzed how these variations affected test accuracy and visually interpreted the results.
-


The completion of Project 4 provided a comprehensive hands-on experience with PointNet architectures, further strengthening skills in 3D vision tasks, neural network implementation, and robustness analysis in the context of point cloud data.
In our course, we've delved in cutting-edge research. This section showcases a selection of academic papers that we've not only read but also reviewed carefully, presented, and discussed in our class. These papers represent a diverse range of topics and discoveries in the field of 3D vision, offering valuable insights.
1. Multi-Scale Geometric Consistency Guided Multi-View Stereo : Explore the world of multi-view stereo reconstruction with a focus on geometric consistency.
2. Structure-from-Motion Revisited : A Fresh Perspective on the role of SFM in Computer Vision.
3. Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets from 3D Scans : Find out how the authors put together datasets for all sorts of vision tasks from 3D scans.
4. What Do Single-view 3D Reconstruction Networks Learn? : Ever wondered what single-view 3D reconstruction networks are up to?
5. Learning Category-Specific Mesh Reconstruction from Image Collections : Dive into category-specific mesh reconstruction from image collections .
6. DynIBaR: Neural Dynamic Image-Based Rendering : Explore DynIBaR, a neural network model that enables realistic dynamic scene synthesis from a single image.
7. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks : Discover 4D Spatio-Temporal ConvNets (Minkowski CNNs) for robust 3D video semantic segmentation using a trilateral space, variational inference, and sparse convolution