This is part of the master's thesis: "A Machine Learning and Point Cloud Processing based Approach for Object Detection and Pose Estimation: Design, Implementation, and Validation", available at AURA UiA.
By combining an RGB image and point cloud data is, the system capable of detecting the object's pose by using object detection, RANSAC and vector operations within the set requirements. This work is based on the YOLOX algorithm and Logistics Objects in Context (LOCO) dataset from 2021 and 2020, respectively.

Figure 1 Is a video of the object detection filtering out the pallet of the point cloud. No pose estimation is performed as the depth data from the Intel RealSense l515 does not capture the ground of the pallet.
The object detection algorithm is the YOLOX-S model from the YOLOX repository, which is transfer learned on the LOCO dataset. The final version is optimized with Intel OpenVINO and implemented together with the pose estimation in C++. A total of two models has been created from the pallet dataset and Table 1 present the YOLOX-S training results for only pallet and pallet void. The pytorch weights are available here.
Table 1: Training results for only_pallet and pallet_void from the LOCO dataset, trained on an NVIDIA GeForce RTX 3060 Laptop GPU.| Model | Parameters | Dataset | Inference time | ||||||
|---|---|---|---|---|---|---|---|---|---|
| yolox_s_only_pallet | 9.0 M | LOCO | 24.0% | 53.2% | 17.2% | 7.9% | 24.3% | 40.6% | 6.74 ms |
| yolox_s_pallet_void | 9.0 M | LOCO | 0.2% | 0.2% | 0.2% | 0.0% | 0.7% | 0.0% | 6.96 ms |
A total of 4 485 images are used for training, containing 86 318 annotations of only pallets, while the validation dataset has a total of 1 006 images and 10 684 annotations. while the validation dataset has a total of 1 006 images and 10 684 annotations.


A total of 1900 pallet holes annotations have been manually annotated, refereed to as voids, split into 1261 training and 639 validation annotations for training. The ML algorithm manage to detect pallet holes, however with a very low confidence bellow 1%, as shown in Figure 3. CVAT support auto labeling with OpenVINO that speed up the labeling process to make the model more confident.
The pose estimation is performed using the object detection algorithm and point cloud data.
Object detection filters out only the relevant points of the pallet where two RANSAC operations are performed. The first plane uses only ground floor points, while the remaining pallet points are used for the second plane. A center vector from the camera is used to find the 3D position where the vector intersects the pallet front plane, while the pallet orientation is directly from the estimated front plane. Figure 4 explains the system outputs in the PCL viewer.
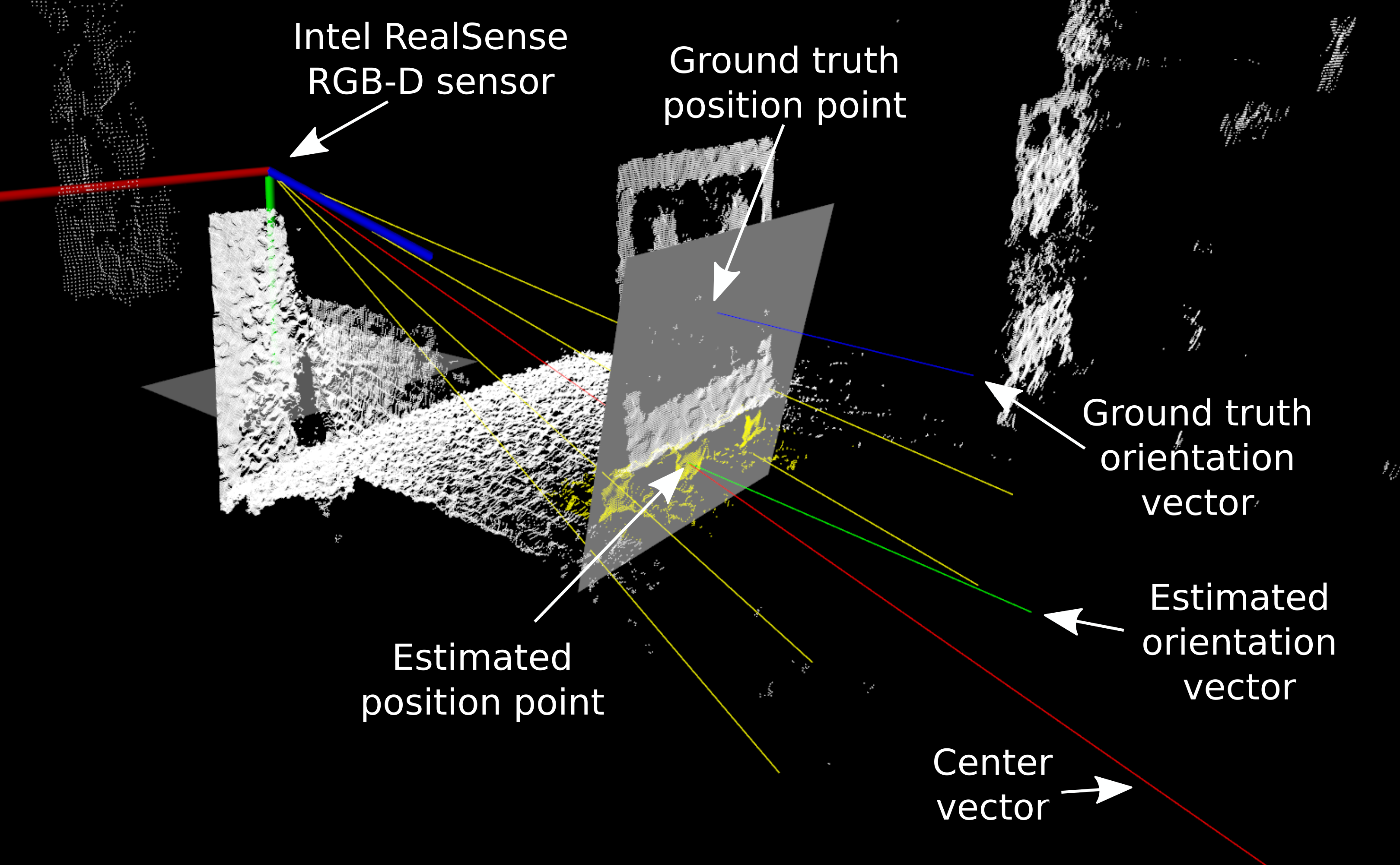
The evaluation of the pose estimation system is done with an AprilTag (Type: 25h9), which can directly output its pose using functions from the OpenCV contrib library. A total of two tests have been performed. Moving test where the camera rotates around from 0 to -90 degrees and a standstill test where accuracy and precision are evaluated. The distance from the pallet is two-meter for both tests. Figure 5 and Figure 6 links to a video.


| Package | Minimum version | Info |
|---|---|---|
| realsense2 | 2.50.0 | From the Intel® RealSense™ SDK 2.0. |
| OpenCV | 4.2.0 | OpenCV_contib is required for aruco module. |
| InferenceEngine | 2021.4.752 | From the OpenVINO toolkit. |
| ngraph | N/A | Required for InferenceEngine, and part of openVINO. |
| PCL | 1.10.0 | From PointCloudLibrary/pcl. |
- Improve the robustness of the system by implementing
- Increasing the range of the pose estimation by using only a single plane and not requiring the ground plane (Dynamic depending on number of remaining points after extraction).
- Detecting pallet holes.
- Make all the vector operations in a single matrix operation.
- Add configuration.
- Add TensorRT based object detection class library for optimized inference on NVIDIA hardware.
- The colors in the image sometimes switch between RGB and BGR. Unknown if this is an issue in the code or in the imported rosbag. The issue is shown in the demo at 01:26.